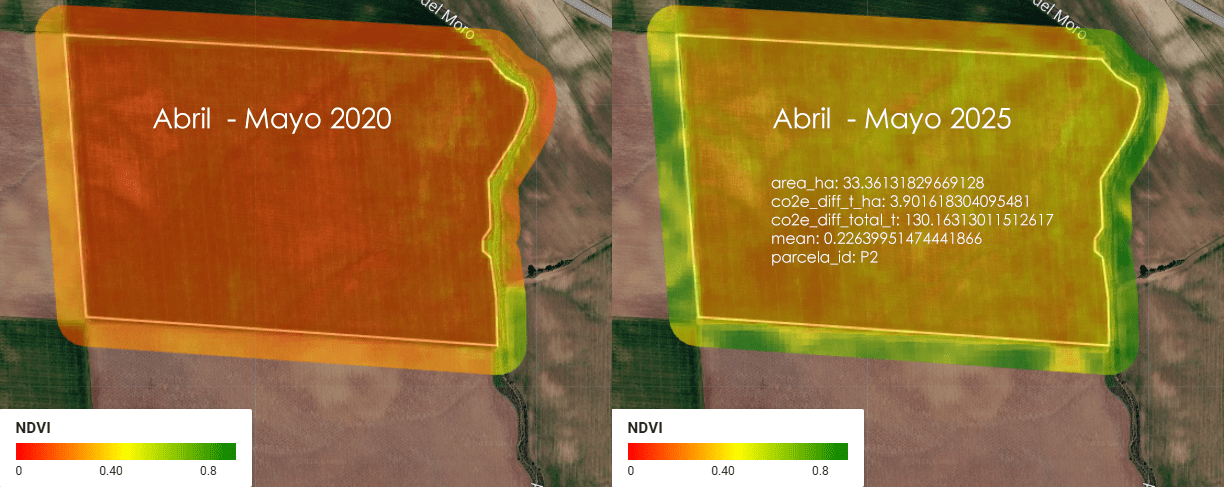
Imagina una empresa que se llama ACME. ACME es dueña de 5 parcelas de tierra en Almendralejo, Extremadura, España, donde se cultiva cereal (trigo, cebada, ese tipo de cosas). Entre las 5 parcelas, ACME tiene un total de 1.52 km² de tierra — para que te hagas una idea, eso es más o menos el tamaño de 300 campos de fútbol (a rzón de aproximadamente media hectárea por cada campo).
Category Archives: Flujos de trabajo /workflows
VENEZUELA EARTHQUAKE RESPONSE using DuckDB, Overture Maps and R
Just wanted to update on the usage of the tool I developed (OVERTURE MAPS EXTRACTOR) for extraction of Open data from Overture Maps for a quick hands on.
Time Series Analyzer: Análisis multitemporal de índices espectrales en Google Earth Engine
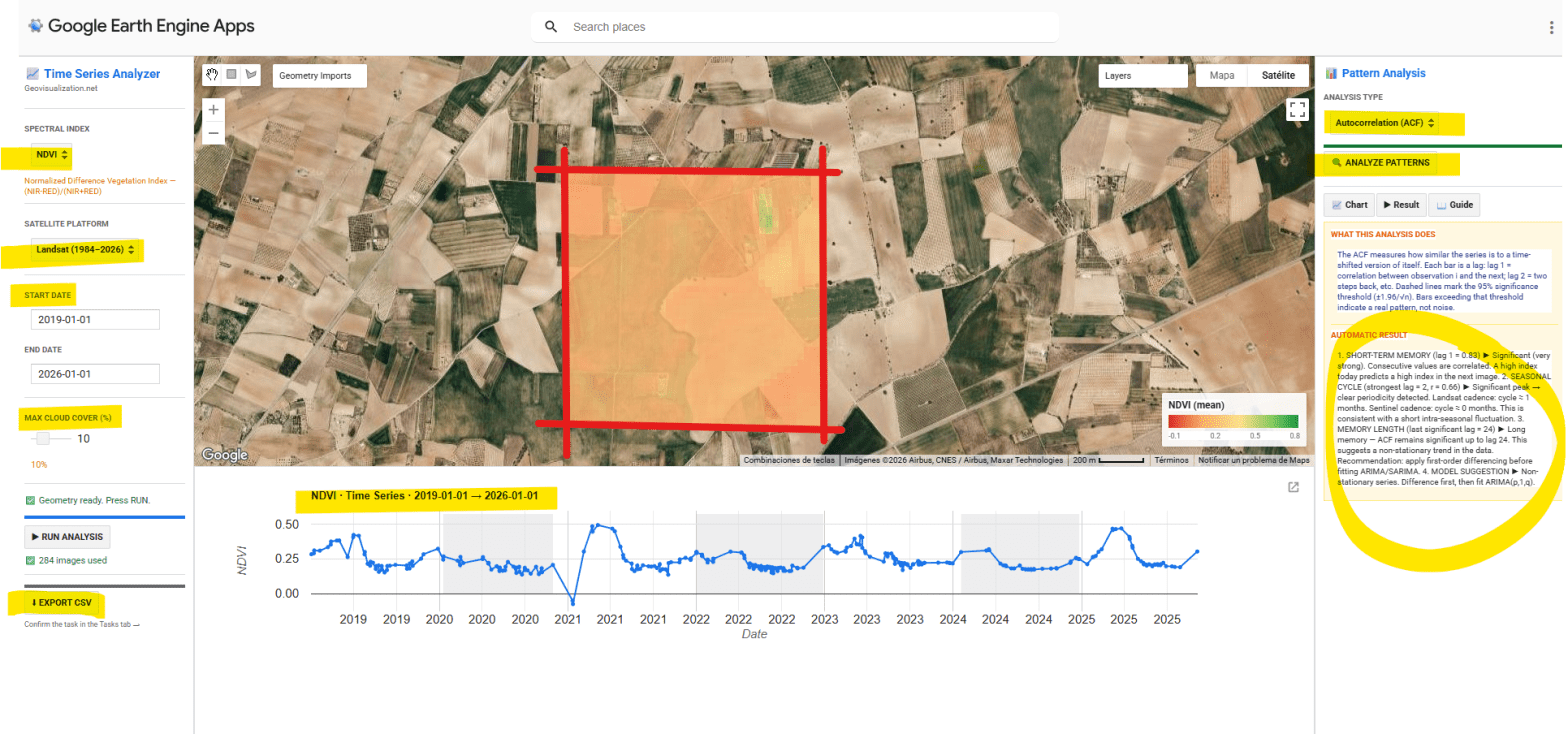
He desarrollado una aplicación interactiva en Google Earth Engine para la extracción y análisis estadístico automático de series temporales de cinco índices espectrales (NDVI, EVI, SAVI, NDWI y NBR) sobre cualquier geometría definida por el usuario en cualquier sitio del mundo. El objetivo es pasar de una imagen satélite puntual a una comprensión temporal del territorio: qué ha pasado, qué patrón subyace, y qué cabe esperar.
CHANGE DETECTION ARCGIS PRO AND LIVING ATLAS 2017-2025
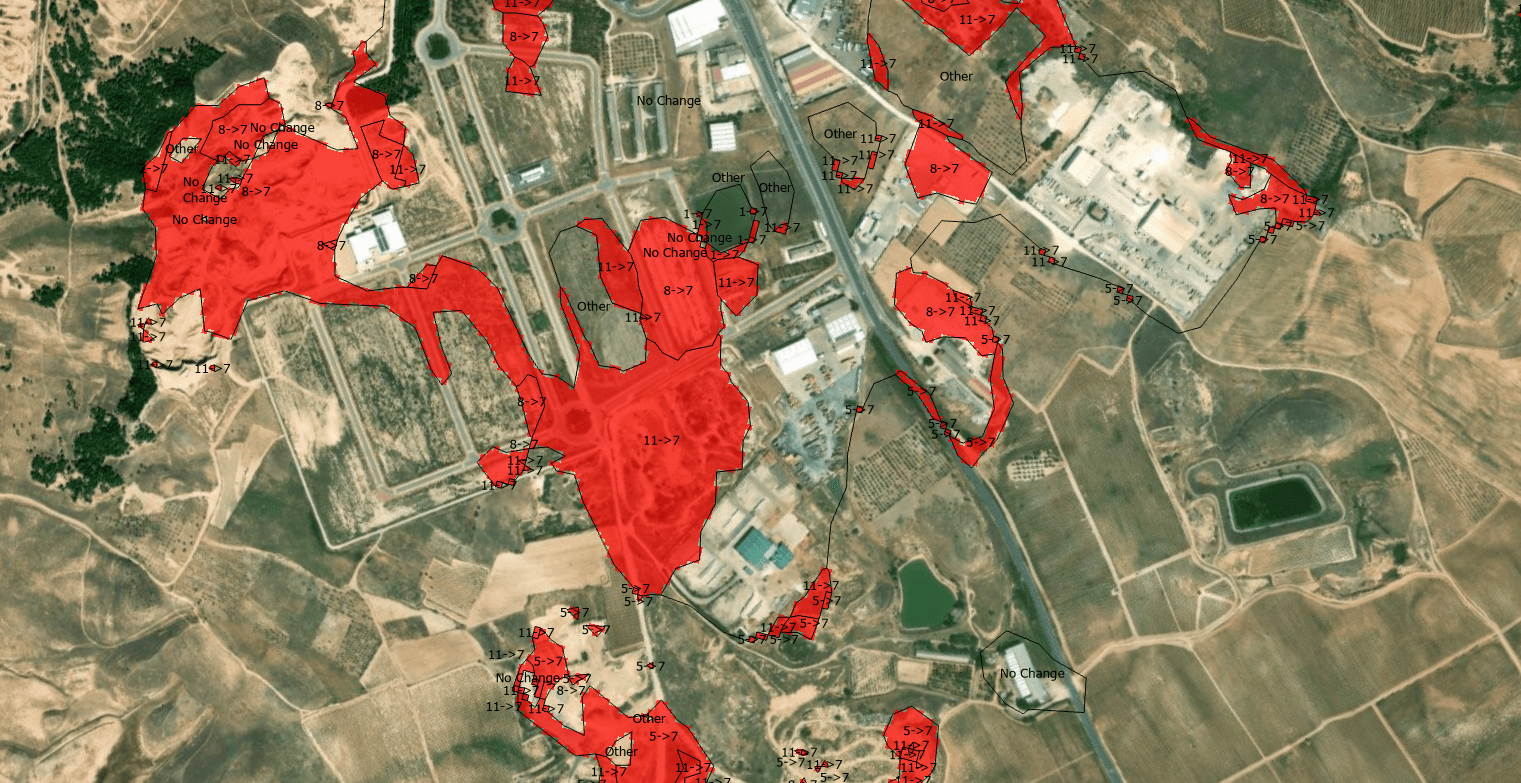
The quantification of land-use dynamics necessitates a spatiotemporal framework that ensures categorical stability over long-term observation windows. The ESRI 10-Meter Global Land Cover time series, accessible through the ArcGIS Living Atlas, provides a harmonized baseline for this purpose, derived from the dense temporal stack of the ESA Sentinel-2 mission.
Aventuras y desventuras de un geógrafo en “desarrollo”
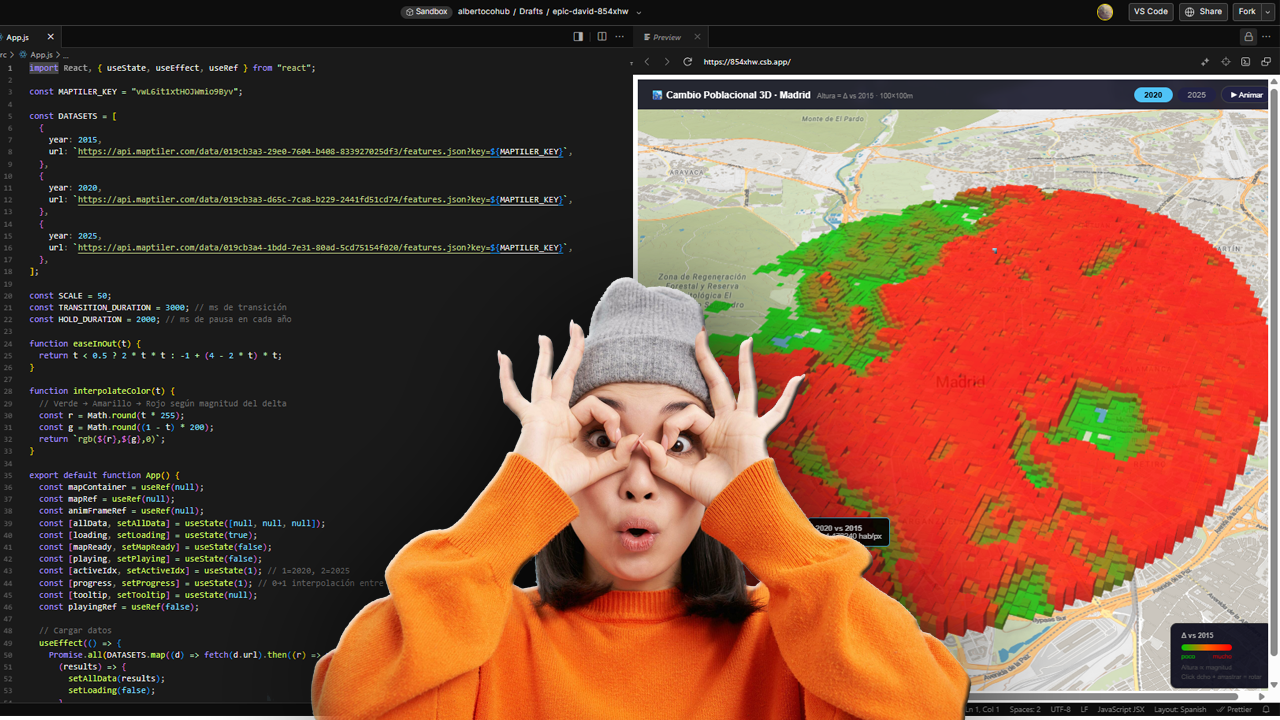
La cartografía siempre ha sido un oficio de precisión, paciencia y criterio espacial. Durante años, el flujo de trabajo de cualquier geógrafo pasaba inevitablemente por entornos de escritorio como ArcGIS Pro o QGIS: cargar capas, ajustar simbología, exportar mapas. Herramientas sólidas, probadas, indispensables. Pero algo está cambiando.
Cada vez más, el análisis espacial ocurre en la nube, en navegadores, en entornos de código. En anteriores post habéis visto algunos test/ideas/aplicaciones que he desarrollado con Javascript Google Earth Engine, que procesa imágenes satelitales a escala planetaria sin mover un solo archivo. Deck.gl y Maplibre renderizan millones de puntos en 3D directamente en el navegador. React convierte un mapa en una aplicación interactiva con pocas líneas de código.
R analysis for HR corporate talent management
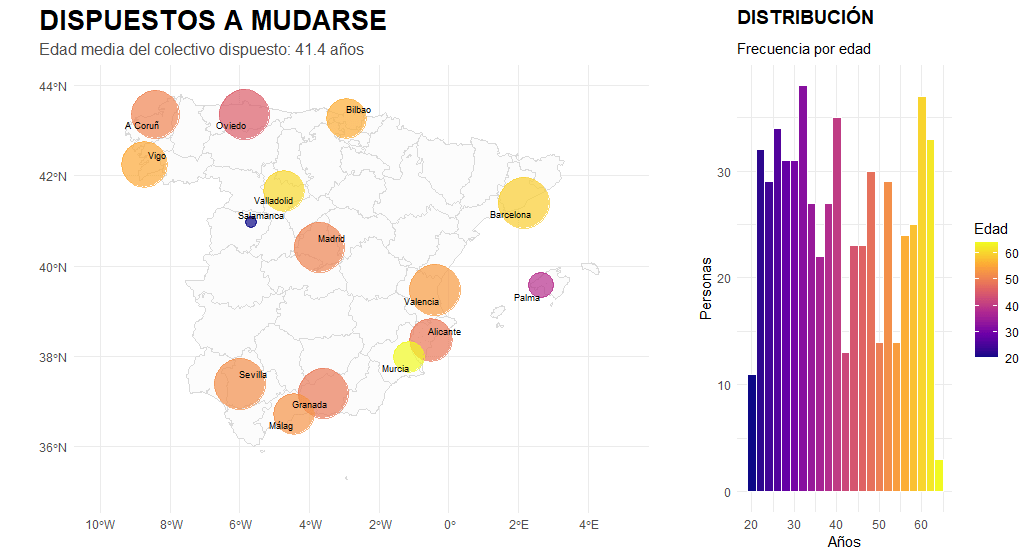
I am a geographer by training, and my professional career has always had a predominantly geospatial focus. Having recently completed a forty-hour course in R, using RStudio and GitHub, I feel that a whole new world of analysis has opened up before me. This work represents the meeting point between my basic geographical instinct and the technical capabilities of statistical programming. It is important to emphasise that I have invented this data and model entirely, so the results have no real meaning and contain inevitable biases. Their sole purpose is to learn and demonstrate the capabilities of this language. I believe that geographical knowledge and code are interdependent, as one without the other would not function successfully. It is precisely this symbiosis that I hope will make a difference in my current job search.
Mapping Something Unthinkable: Flood Risk in Madrid using Open Data

Dont get wrong if you see the IA background showing our handsome major almost showing his beautiful smile in Cibeles/Correos it’s only to get your attentions (only if you need it thou!). Flooding in urban environments is not a speculative hazard but something we can quantify. In the case of Madrid, the intersection of pretty mountainous terrain (it might surprise you there are 2000m difference between the highest spot in Madrid province, Pico Peñalara -2428m- and the Alberche river environment in some areas -430m-) and urban expansion presents a scenario of significant risk, particularly when analyzed through the lens of shared high-resolution geospatial data. This study integrates the buildings from BTN (Base Topográfica Nacional) provided by the Spanish “IGN”, the CNIG with the official flood hazard maps for a 100-year return period (T=100), published by the Ministry for the Ecological Transition and the Demographic Challenge (MITECO). The T=100 scenario is the most representative for evaluating long-term flood exposure, as it reflects events with a 1% annual probability—rare but not improbable, and certainly not negligible.
Agricultura de Precisión (I). Uso del Satélite para la toma de decisiones en el campo

Quieres conocer cuál es el momento óptimo para plantar? Para fumigar? Para recolectar?. Sabías que dos de cada tres agricultores no cosechan en la fase de madurez adecuada?. Aquí abajo te describo un método completamente automatizado mediante el uso combinado de varios índices de vegetación como NDVI, NDWI, SAVI y EVI que podemos extraer del Satétile SENTINEL-2 en la plataforma COPERNICUS de la UE para conocer exactamente y anticipar las mejores decisiones de intervención sobre tus tierras.
Sentinel-1 SAR: Un aliado indispensable para el análisis y seguimiento de inundaciones – Derna, Libia (2023)

La gestión y monitorización de fenómenos hidrológicos extremos, como inundaciones repentinas o fallos estructurales en presas, representan un desafío crítico para los especialistas en geomática, hidrología y planificación territorial. En este contexto, la tecnología radar de apertura sintética (SAR) a bordo del satélite Sentinel-1 de la Agencia Espacial Europea (ESA) ofrece una capacidad sin precedentes para capturar información precisa y fiable sobre la dinámica superficial, independientemente de las condiciones atmosféricas y lumínicas.
Urban delineation methods beyond administrative boundaries
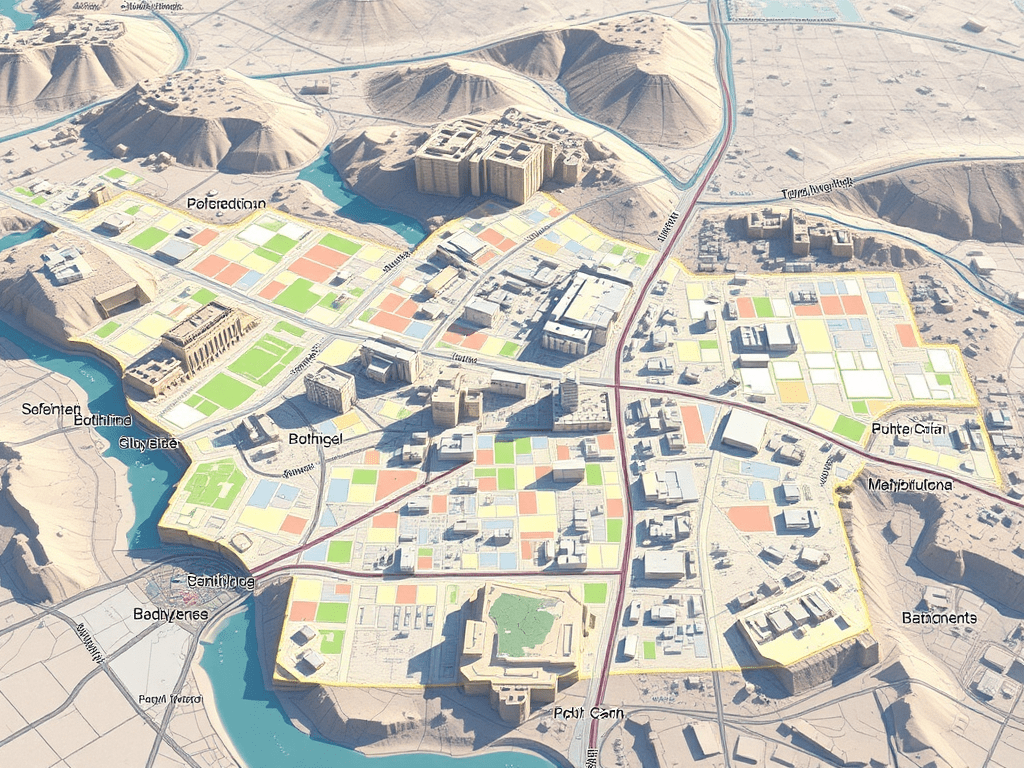
As a geographer working with Geographic Information Systems (GIS), I am particularly interested in exploring urban delineation methods that move beyond the constraints of administrative boundaries. Instead of relying on official municipal limits—which can often be outdated or misaligned with functional realities on the ground—I focus on delineating urban areas based on physical indicators such as built-up surface, population density, and spatial continuity. This approach allows for a more accurate and dynamic understanding of urban space.
