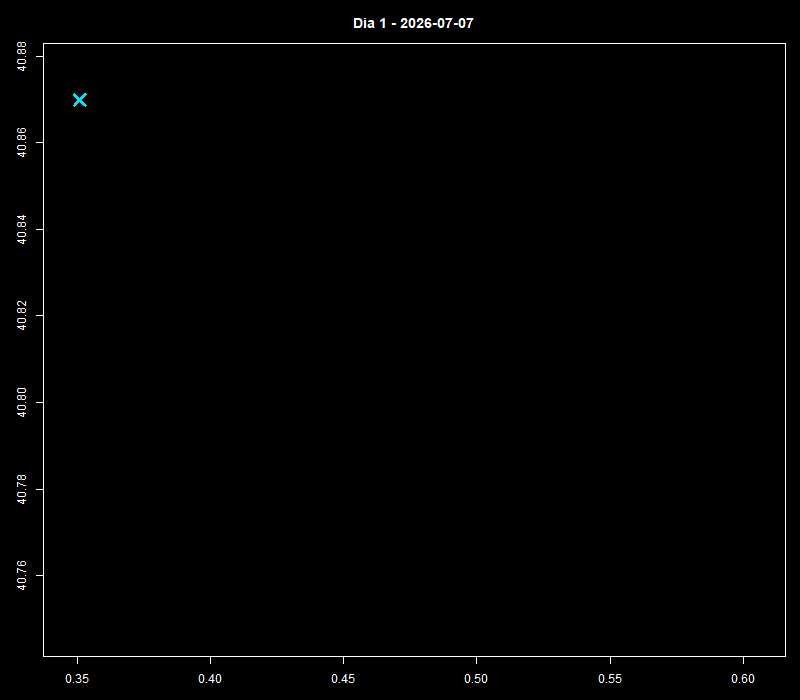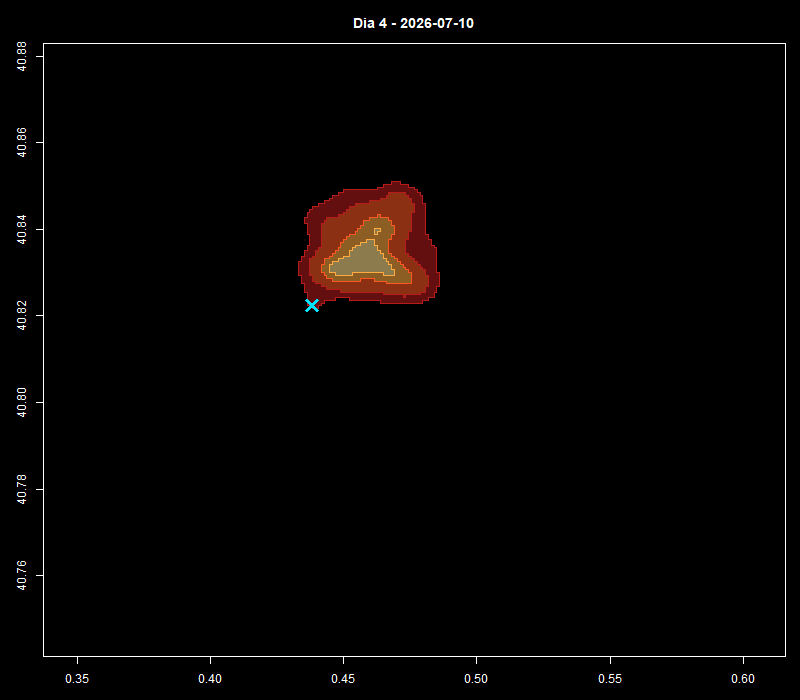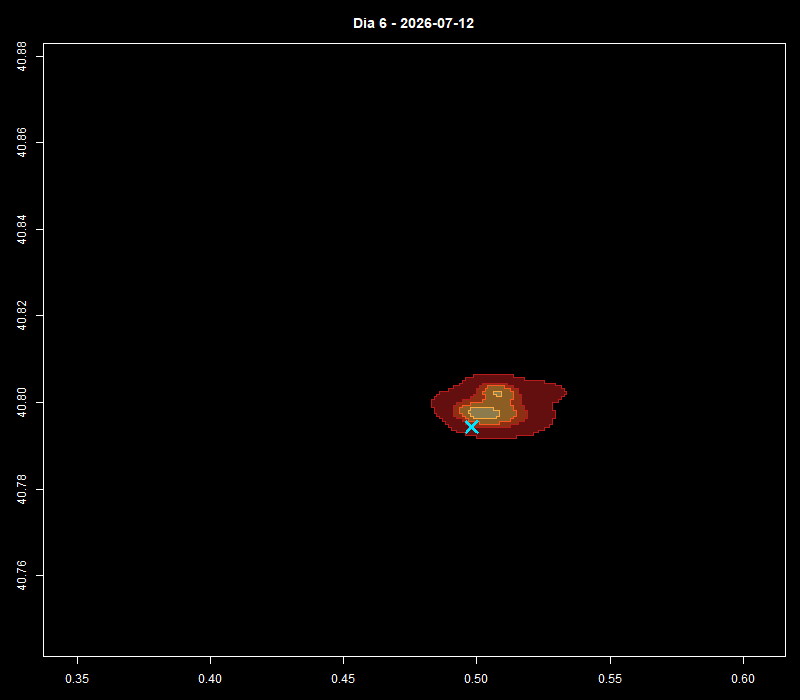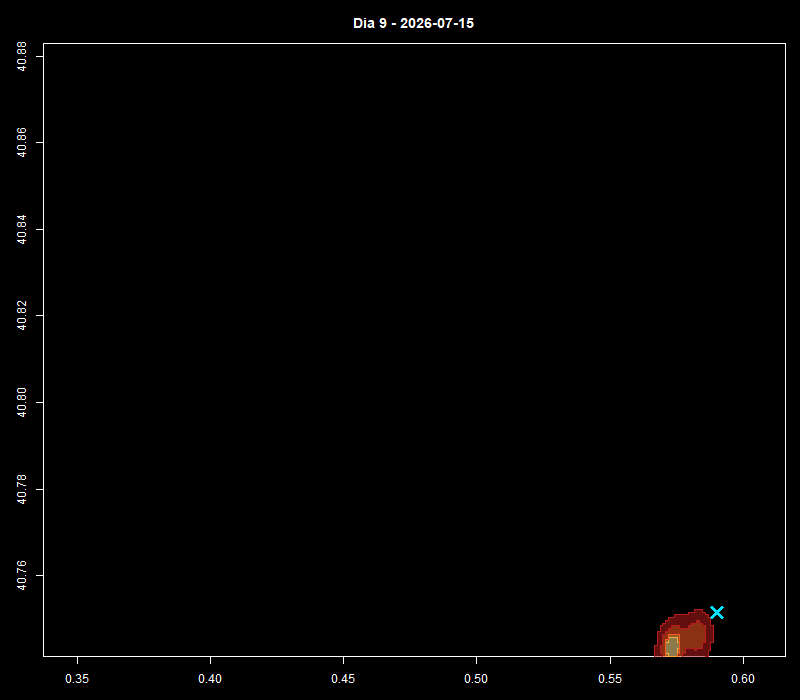
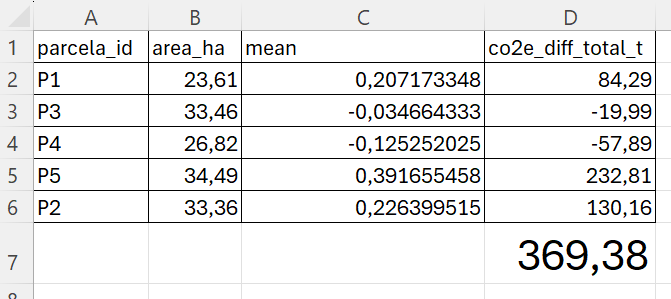
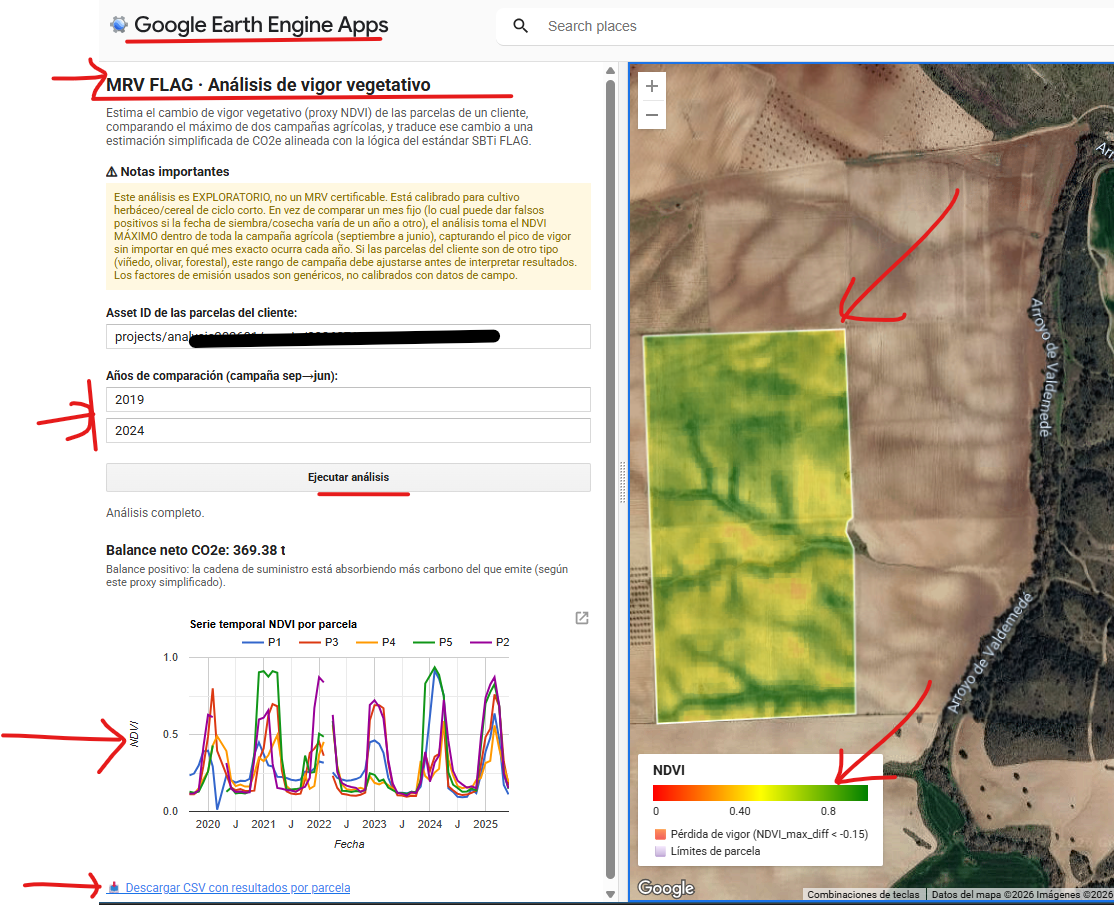
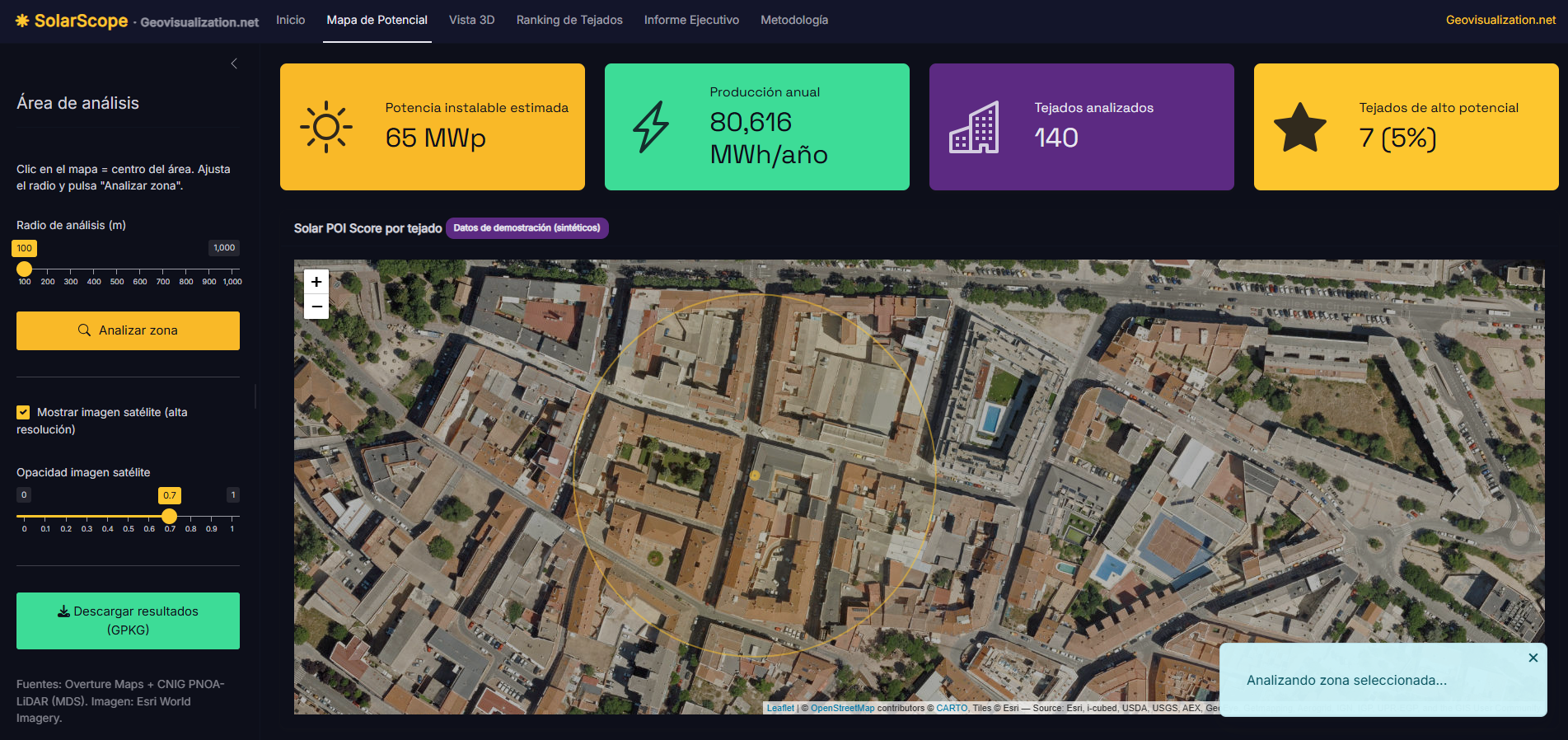
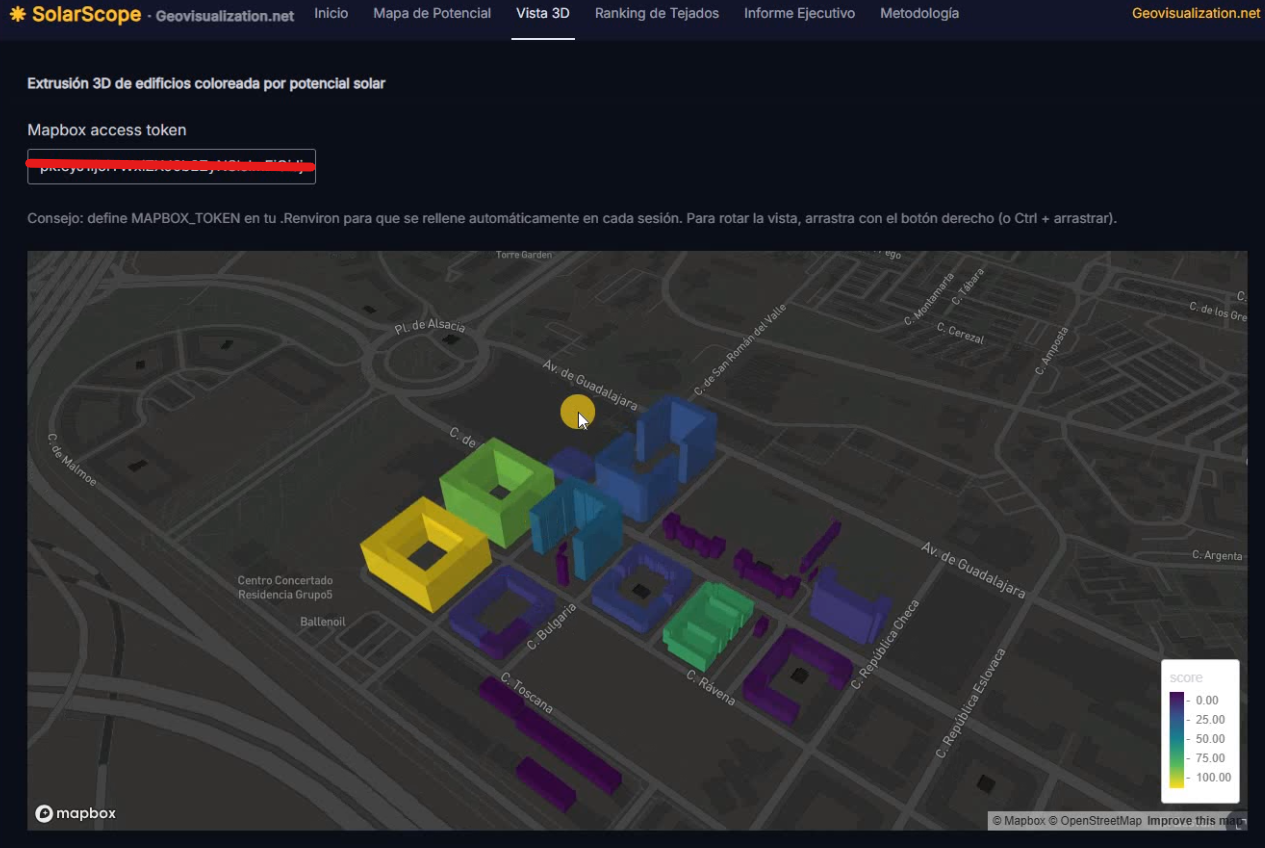
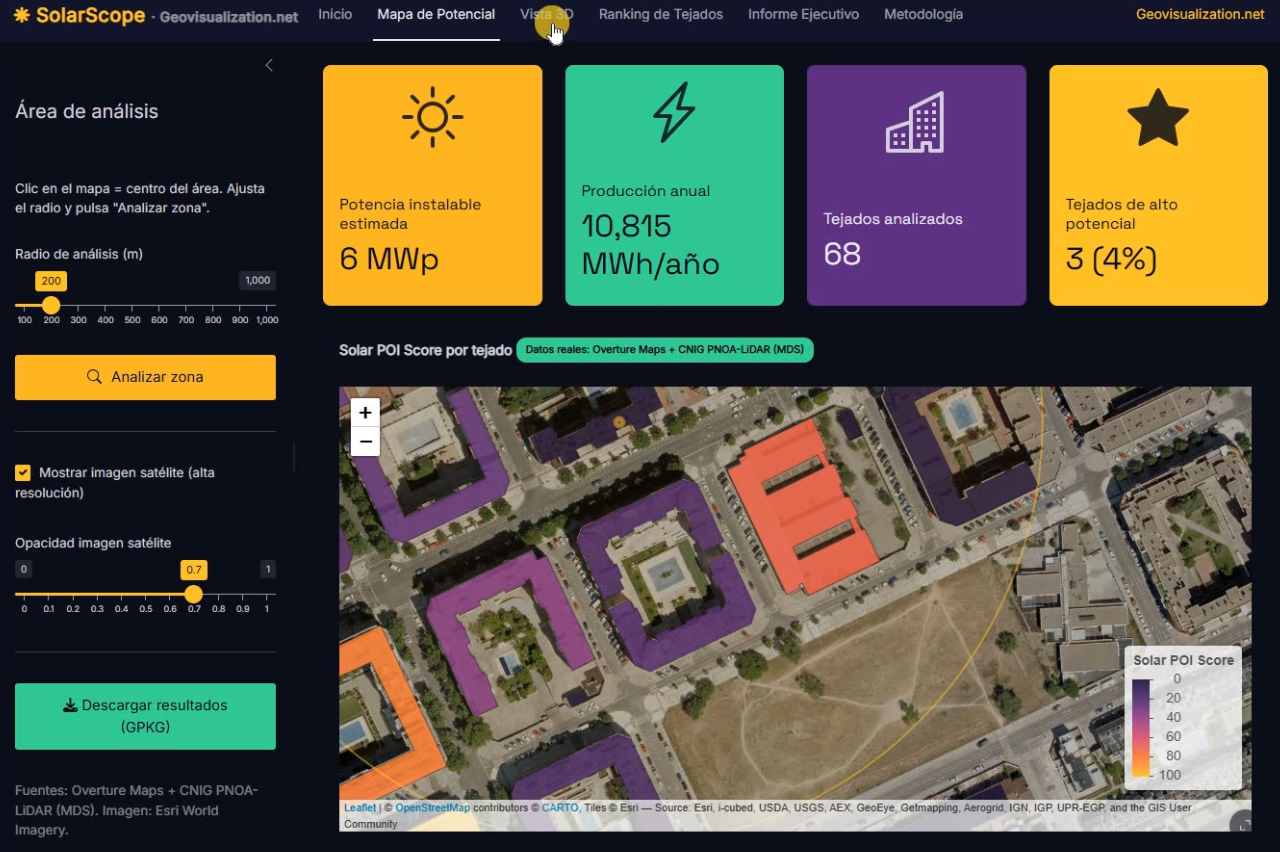
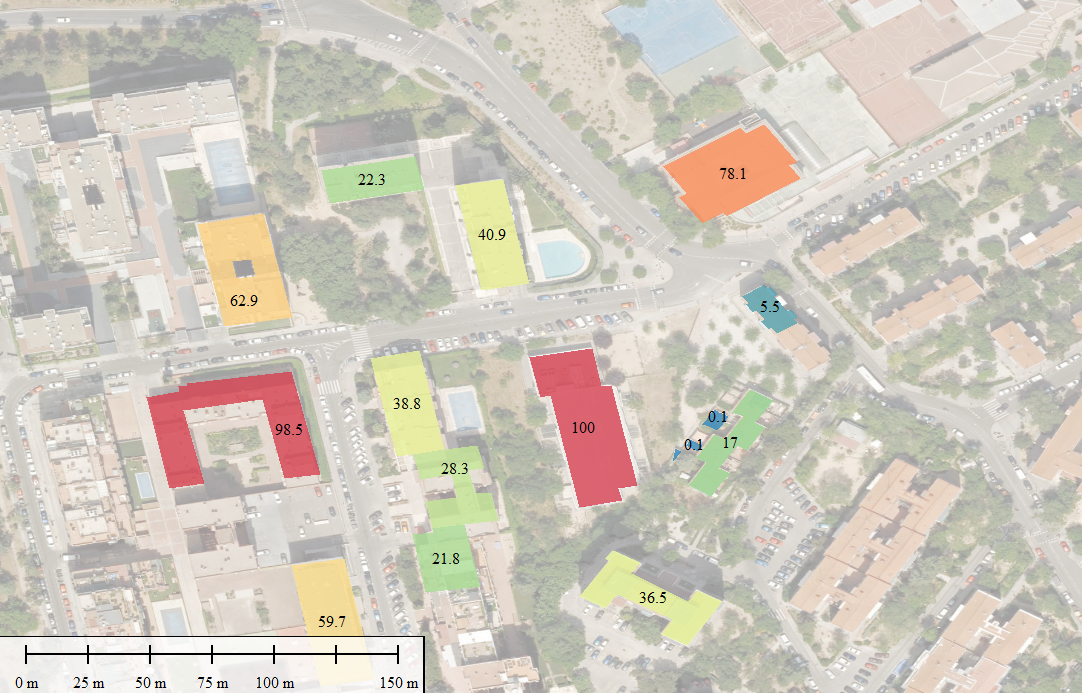
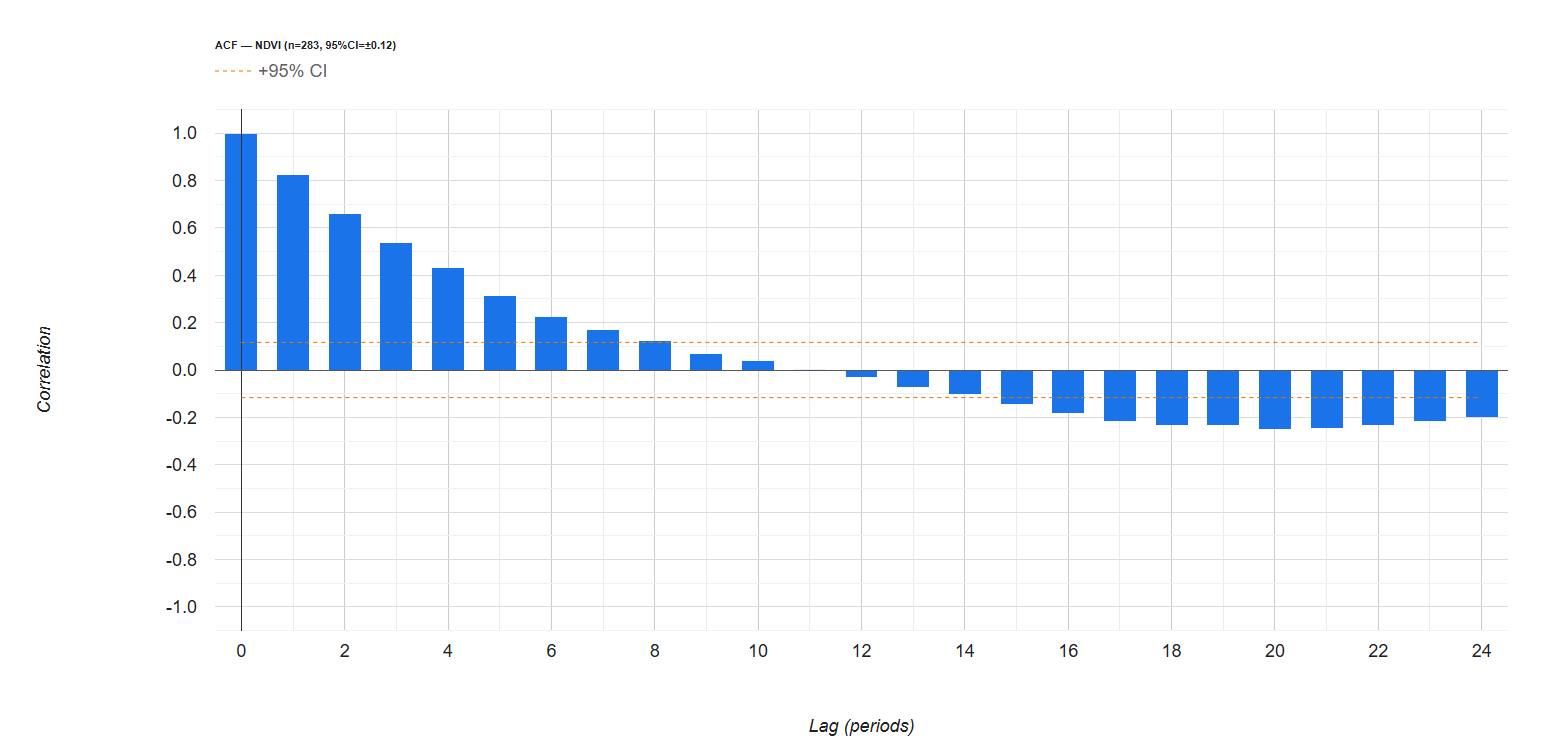
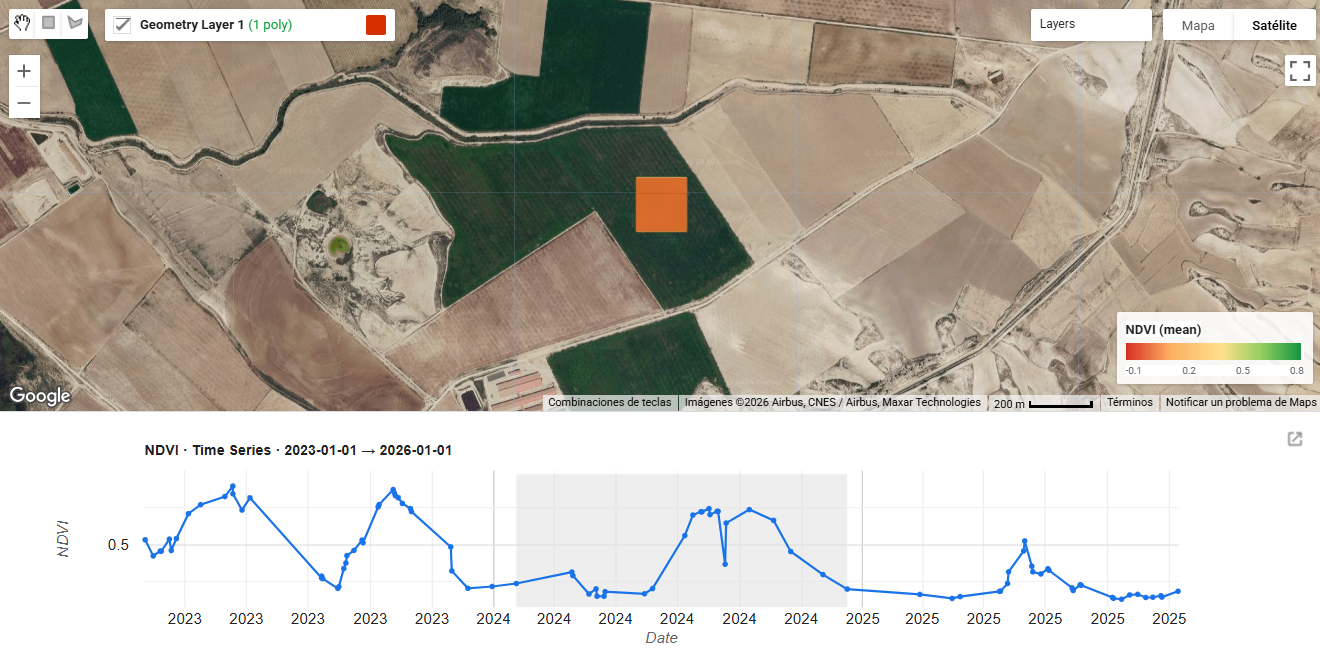
El análisis de la distribución espacial de servicios financieros en centros urbanos —bancos, cajeros, aseguradoras, gestorías y corredurías de seguros— ofrece una lectura directa de la vitalidad económica y la accesibilidad financiera de un territorio. Mapear estos puntos con assetIQ sobre datos Overture Maps permite identificar en minutos dónde se concentra la actividad financiera, qué zonas quedan en la periferia del servicio y cómo se estructuran los ejes comerciales de cada ciudad. El mismo análisis es replicable para cualquier otra capa temática —alojamiento, salud, restauración, deporte— convirtiendo cada capital de provincia en un dashboard geoespacial comparable y reproducible.
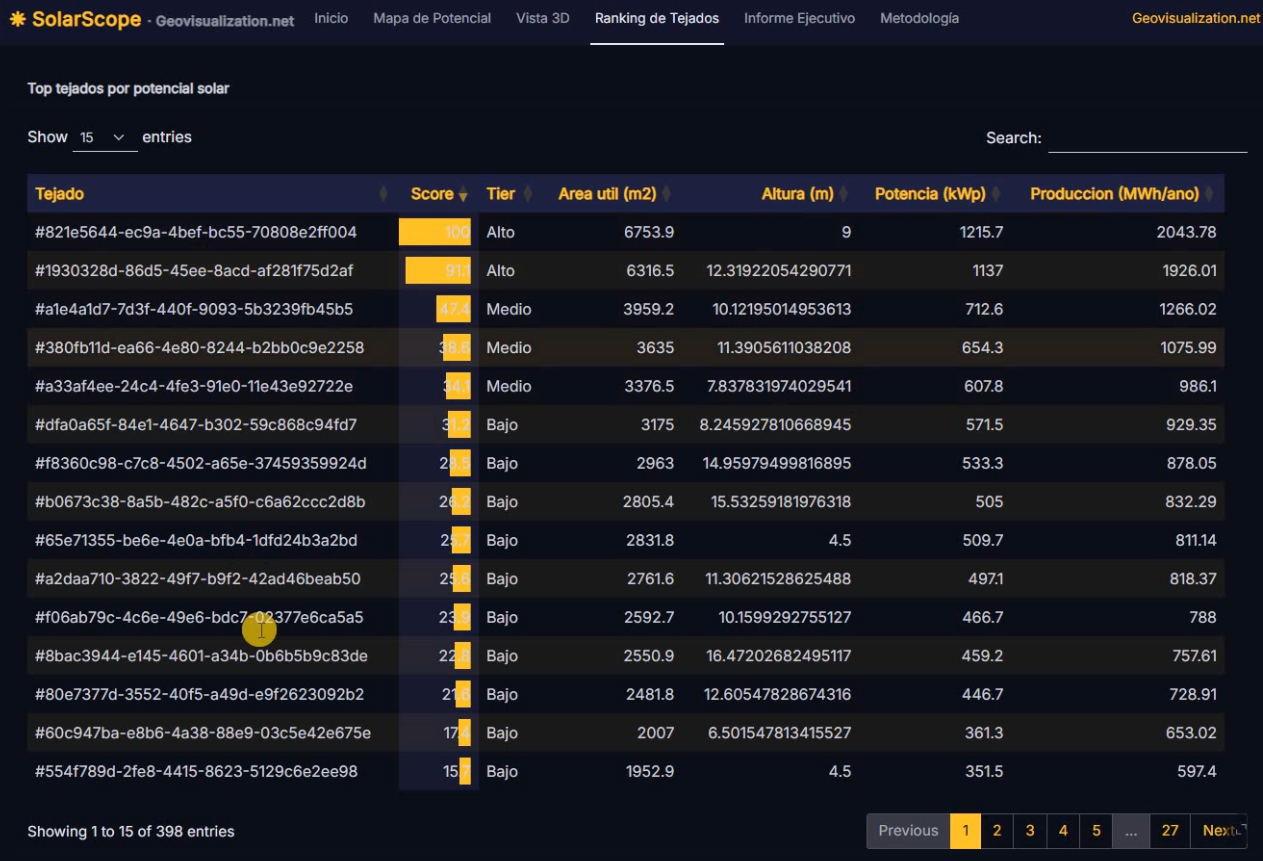
Más allá de la visualización individual por categoría, assetIQ calcula para cada edificio del área de interés un índice POIQ (POI Quality Index), un valor normalizado entre 0 y 1 derivado de la densidad de kernel de cada grupo temático en su entorno inmediato. Esto permite construir una matriz de correlación entre todas las categorías —Finanzas, Comercio, Alimentación, Salud, Alojamiento, etc.— midiendo mediante Pearson o Spearman en qué medida la concentración de un tipo de actividad coexiste o se excluye con otra. Una correlación alta entre Finanzas y Comercio en el mismo edificio o entorno indica sinergia espacial —los dos usos se retroalimentan y comparten eje urbano—; una correlación baja o negativa entre Alojamiento y Servicios Industriales señalaría segregación funcional. Esta capa analítica transforma la visualización de puntos en una herramienta de inteligencia urbana cuantificada, útil para inversores, entidades financieras en expansión, planificadores urbanos o consultores de localización que necesitan comparar ciudades de forma reproducible y objetiva.
Vamos a recorrer esta preciosa región a la que tengo tanto cariño y donde me licencié en su facultad de Geografía (en los Leones!) en Valladolid. Una por una y en orden alfabético para que nadie se queje 🙂
Ávila — El dinero dentro de las murallas

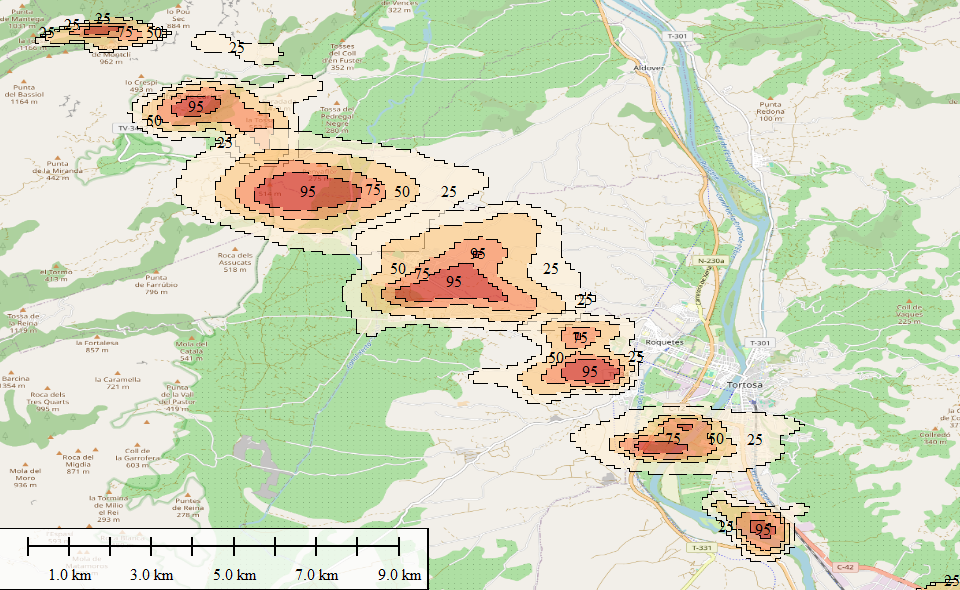
Con 73 POIs financieros sobre un total de 2.058 (3,54%) en un radio de 3 km, Ávila muestra una concentración financiera muy marcada en el centro histórico, coherente con su estructura urbana compacta. El heatmap revela dos núcleos calientes claramente diferenciados: uno en torno al eje de la Plaza de Santa Teresa / Puerta del Alcázar, donde se agrupan las sucursales bancarias tradicionales, y un segundo foco algo más desplazado hacia el norte que probablemente corresponde a la zona de expansión comercial moderna. La categoría dominante es banks y financial_service, con presencia notable de atm y insurance_agency. El median center cae dentro del recinto amurallado, lo que confirma que el grueso de la oferta financiera sigue anclado al tejido histórico-comercial, sin haber migrado aún hacia las nuevas áreas residenciales del extrarradio. Para una ciudad de este tamaño, 73 registros financieros es una densidad razonable pero con escasa redundancia —cualquier cierre de sucursal tiene impacto real en la accesibilidad del servicio.Con 73 POIs financieros sobre un total de 2.058 (3,54%) en un radio de 3 km, Ávila muestra una concentración financiera muy marcada en el centro histórico, coherente con su estructura urbana compacta. El heatmap revela dos núcleos calientes claramente diferenciados: uno en torno al eje de la Plaza de Santa Teresa / Puerta del Alcázar, donde se agrupan las sucursales bancarias tradicionales, y un segundo foco algo más desplazado hacia el norte que probablemente corresponde a la zona de expansión comercial moderna. La categoría dominante es banks y financial_service, con presencia notable de atm y insurance_agency. El median center cae dentro del recinto amurallado, lo que confirma que el grueso de la oferta financiera sigue anclado al tejido histórico-comercial, sin haber migrado aún hacia las nuevas áreas residenciales del extrarradio. Para una ciudad de este tamaño, 73 registros financieros es una densidad razonable pero con escasa redundancia —cualquier cierre de sucursal tiene impacto real en la accesibilidad del servicio.
Burgos — Dos ciudades, dos bancas

Con 145 POIs financieros sobre 4.202 totales (3,45%) en un radio de 3 km, Burgos duplica en volumen absoluto a Ávila manteniendo una proporción relativa casi idéntica, lo que sugiere que el peso del sector financiero en el tejido urbano de las capitales castellanas tiende a estabilizarse en torno al 3,5% independientemente del tamaño. El heatmap es especialmente revelador: muestra dos núcleos claramente separados en lugar de uno, con un foco principal muy intenso en el centro histórico —eje Paseo del Espolón / Calle Vitoria, el corredor comercial y bancario por excelencia de la ciudad— y un segundo núcleo de menor intensidad hacia el sur, en la zona de
Gamonal, el barrio obrero y comercial más poblado de Burgos. Esta dualidad refleja la estructura socioeconómica real de la ciudad: banca tradicional y de gestión patrimonial concentrada en el centro, banca minorista y cajeros orientados al consumo cotidiano en Gamonal. El median center se desplaza hacia el oeste respecto al centro geométrico del buffer, ajustándose al eje financiero real. La presencia de business_banking_service y tax_services entre las categorías más frecuentes apunta a una demanda corporativa relevante, coherente con el perfil industrial y logístico de Burgos como nodo de la A-1.
León — La red financiera que siguió a la población
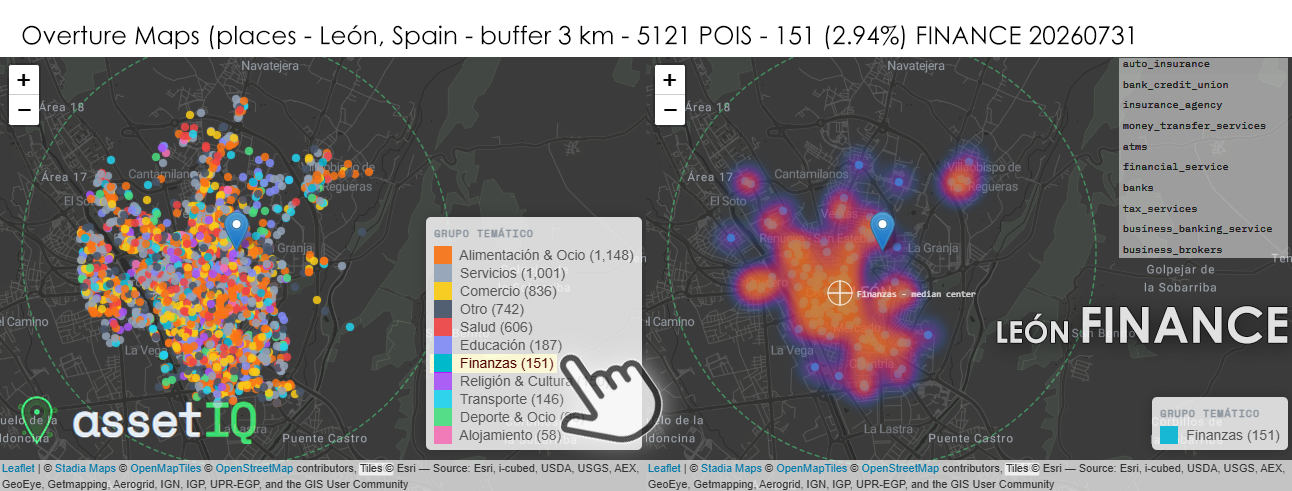
Con 151 POIs financieros sobre 5.121 totales (2,94%) en un radio de 3 km, León presenta la proporción relativa más baja de las tres primeras ciudades analizadas, lo que resulta llamativo dado que es la capital más poblada del grupo. Este descenso porcentual puede indicar una mayor diversificación del tejido urbano —más peso de servicios, hostelería y comercio— que diluye el peso relativo del sector financiero, o bien una menor densidad de sucursales físicas fruto de la digitalización bancaria más acelerada en ciudades medianas con población envejecida. El heatmap muestra un patrón más fragmentado y difuso que el de Burgos: hay un núcleo caliente principal en torno al eje Ordoño II / Calle Ancha, el corredor financiero y comercial histórico de León, pero con varios satélites de intensidad media dispersos hacia el norte y el noreste, en los barrios de expansión residencial. Esta dispersión sugiere que la banca minorista ha seguido a la población hacia los nuevos desarrollos urbanos más activamente que en otras capitales. El median center se posiciona con precisión sobre el centro comercial consolidado, aunque la nube de puntos secundarios le resta nitidez al análisis de concentración. La presencia de bank_credit_union entre las categorías destacadas es notable — inusual en ciudades de este tamaño en España y podría apuntar a entidades de crédito cooperativo con implantación regional fuerte en Castilla y León.
Palencia — Más bancos de los que el tamaño explica
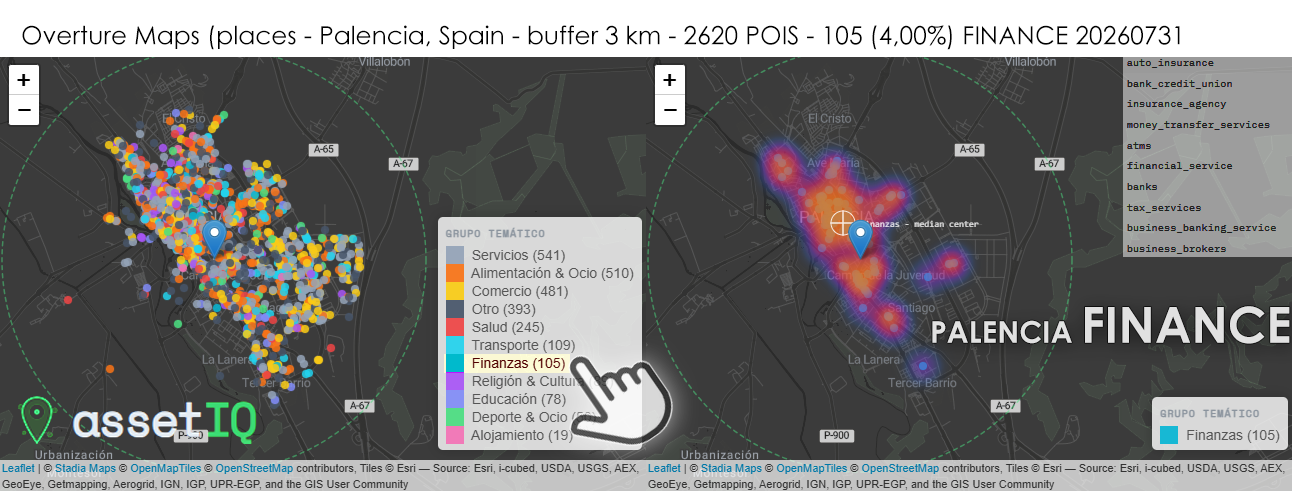
Con 105 POIs financieros sobre 2.620 totales (4,00%) en un radio de 3 km, Palencia registra la proporción relativa más alta de las capitales analizadas hasta ahora, superando el umbral del 4% — dato significativo para una ciudad de apenas 75.000 habitantes. Esto sugiere que el sector financiero está sobredimensionado respecto al tamaño urbano, posiblemente como herencia de una época de mayor actividad económica industrial y agraria en la que Palencia actuaba como plaza bancaria de referencia para toda su provincia. El heatmap es el más concentrado y compacto del grupo: un núcleo central de altísima densidad en torno a la Calle Mayor y el eje Calle Menéndez Pelayo, con dos lóbulos secundarios bien definidos al norte y al sur que siguen perfectamente el trazado del ensanche urbano histórico. Esta morfología de “trébol” es característica de ciudades con estructura urbana lineal a lo largo de un eje principal. El median center coincide prácticamente con el centro geométrico del núcleo financiero, lo que indica una distribución excepcionalmente equilibrada sin outliers que lo desplacen. Destaca la presencia de atm como categoría muy frecuente — inusualmente alta para el tamaño de la ciudad — lo que podría reflejar una red de cajeros sobredimensionada respecto a la demanda actual, un indicador típico de territorios en proceso de contracción demográfica donde las entidades mantienen infraestructura física heredada.
Salamanca — El Toro manda: concentración sin fisuras
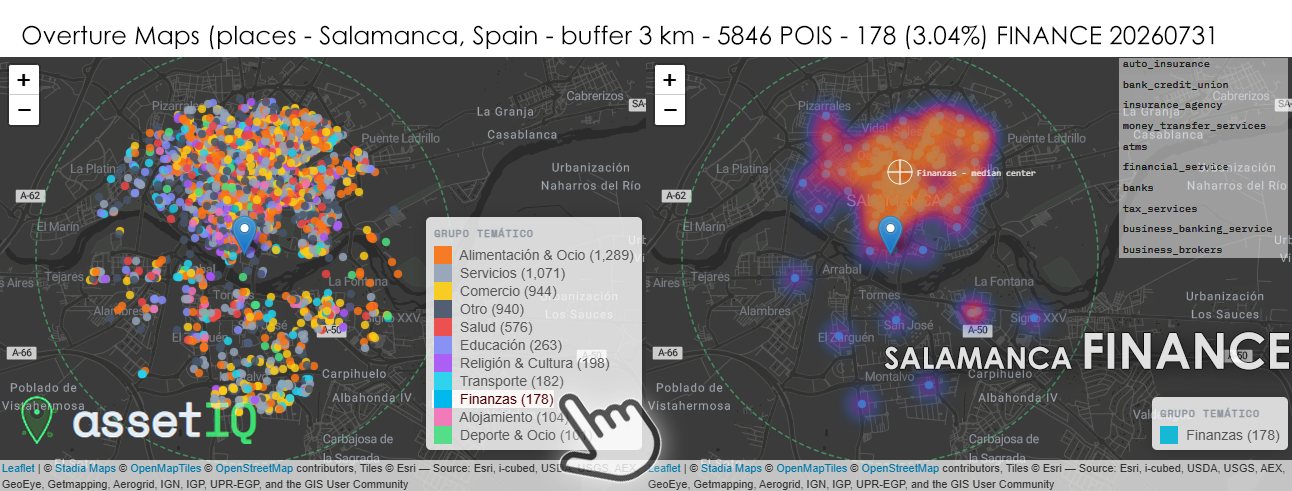
Con 178 POIs financieros sobre 5.846 totales (3,04%) en un radio de 3 km, Salamanca es la ciudad con mayor volumen absoluto de servicios financieros del grupo hasta ahora, aunque su proporción relativa se mantiene en la media del conjunto. Lo verdaderamente distintivo aquí es la morfología del heatmap: un núcleo único de densidad extraordinariamente alta, compacto, casi circular, centrado sobre el eje Gran Vía / Calle Toro — el corredor financiero y comercial más potente de Castilla y León fuera de Valladolid. La ausencia de lóbulos secundarios relevantes indica que la actividad financiera en Salamanca no se ha descentralizado: todo permanece anclado en el centro histórico consolidado, posiblemente reforzado por la demanda de una población universitaria numerosa que genera una necesidad constante de servicios bancarios minoristas, cambio de divisa e insurance_agency vinculados a alquiler residencial. El median center se desplaza claramente al norte respecto al marcador de posición, confirmando que el peso financiero real está en la mitad norte del buffer — la ciudad histórica — y no en los desarrollos del sur del Tormes. La categoría money_transfer_services tiene aquí una presencia destacada, coherente con una ciudad universitaria con alta proporción de estudiantes internacionales que necesitan remesas y transferencias internacionales con frecuencia.
Segovia — La topografía parte el mapa financiero en dos
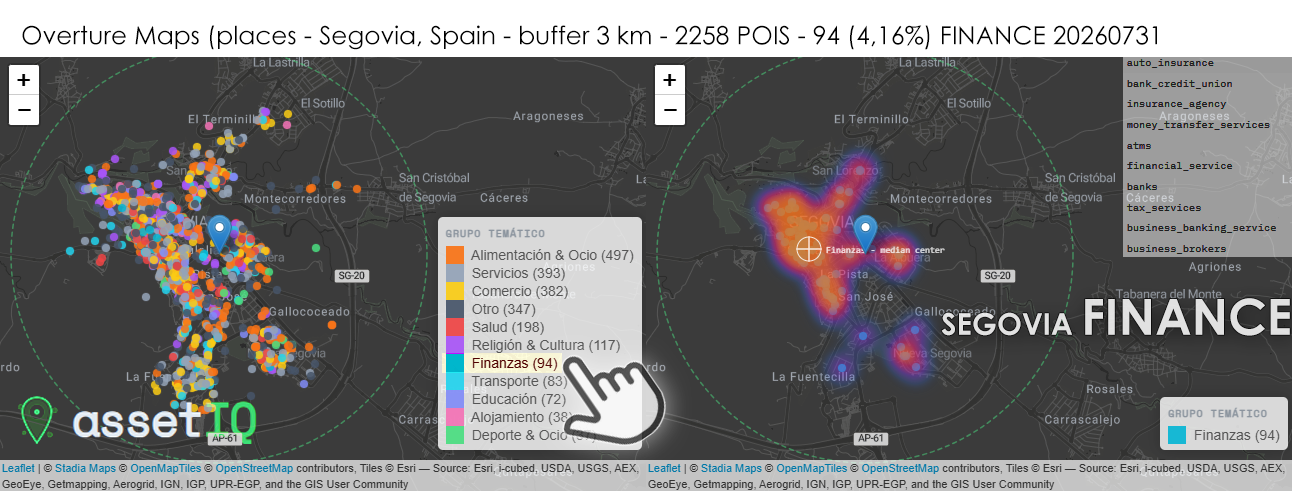
Con 94 POIs financieros sobre 2.258 totales (4,16%) en un radio de 3 km, Segovia comparte con Palencia el honor de superar el umbral del 4% de concentración financiera relativa, siendo junto a ella la ciudad con mayor densidad proporcional del grupo. Para una ciudad de apenas 50.000 habitantes esto es llamativo y merece interpretación: Segovia actúa históricamente como capital administrativa y judicial de una provincia amplia y dispersa, lo que genera una demanda de servicios financieros formales —notarías, gestorías, banca de empresa agraria— que va más allá de lo que su población residente justificaría por sí sola. El heatmap muestra un patrón bilobulado muy nítido: un núcleo principal de alta intensidad sobre el eje de la Calle Real y la Plaza Mayor —el corredor financiero histórico intramuros— y un segundo foco claramente separado hacia el sur, en el ensanche moderno de San José / La Fuentecilla, donde la banca minorista ha seguido el crecimiento residencial de las últimas décadas. La separación física entre ambos núcleos es más pronunciada que en cualquier otra ciudad del grupo, reflejo de la topografía segoviana que impone una ruptura urbana real entre la ciudad histórica sobre el cerro y la ciudad moderna en el llano. El median center cae precisamente en el valle entre ambos núcleos, un punto que geográficamente no corresponde a ninguna concentración real — lo que ilustra perfectamente la limitación del centroide en distribuciones bimodales y refuerza el valor del heatmap como herramienta complementaria.
Soria — Todo en el Collado, nada más allá
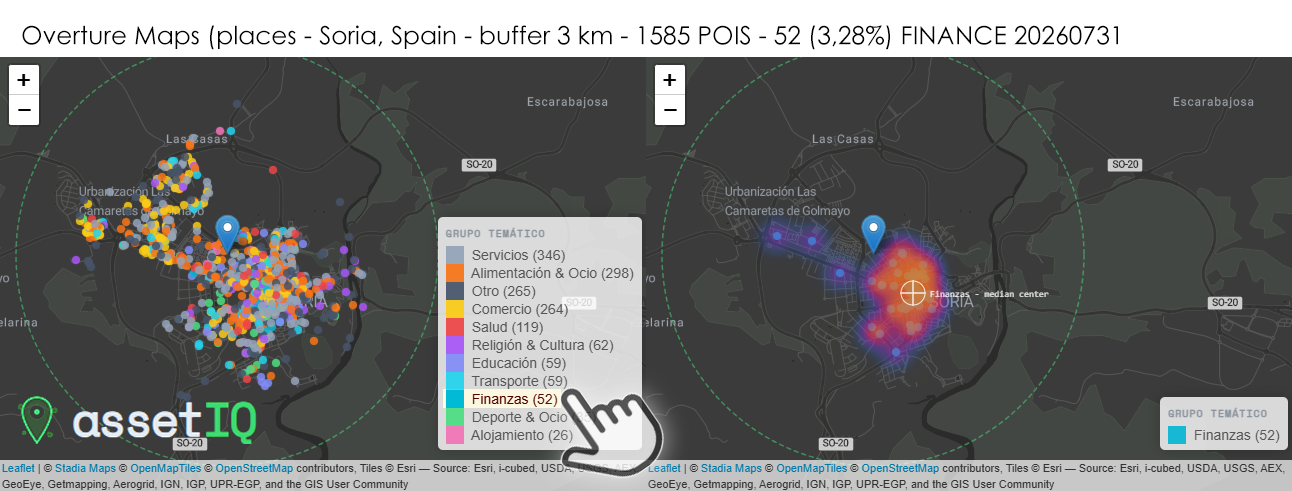
Con 52 POIs financieros sobre 1.585 totales (3,28%) en un radio de 3 km, Soria es la ciudad con menor volumen absoluto del grupo, reflejo directo de ser la capital de provincia menos poblada de España con apenas 38.000 habitantes. Sin embargo, su proporción relativa del 3,28% se mantiene dentro de la banda central del conjunto, lo que indica que el tejido financiero, aunque pequeño, está presente de forma proporcionalmente coherente. El heatmap es el más monocéntrico y concentrado de todas las capitales analizadas: un único núcleo de densidad muy alta, casi perfectamente circular, centrado sobre el Collado —la calle peatonal principal de Soria— sin ningún lóbulo secundario de relevancia. Esta morfología de punto único es la expresión geoespacial de una ciudad que no ha experimentado descentralización urbana real: todo el comercio, la administración y los servicios financieros permanecen en el casco histórico compacto, sin expansión hacia barrios periféricos con entidad propia. El median center coincide prácticamente con el centroide visual del núcleo, algo que solo ocurre en distribuciones perfectamente unimodales como esta. Llama la atención que con tan solo 52 registros, Soria cuente con una representación completa de subcategorías —banks, atm, insurance_agency, tax_services, business_banking_service— lo que indica que todas las tipologías de servicio financiero están presentes aunque con un único representante por tipo, una situación de mínima redundancia y máxima vulnerabilidad ante cierres o reubicaciones.
Valladolid — La capital que no necesita un solo centro
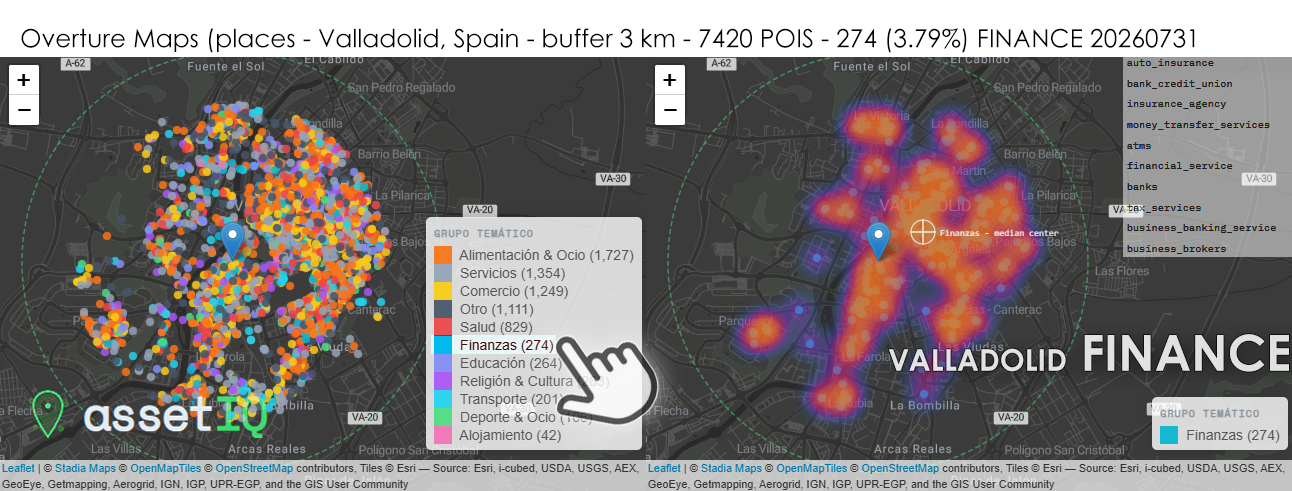
Con 274 POIs financieros sobre 7.420 totales (3,79%) en un radio de 3 km, Valladolid es con claridad la capital financiera de Castilla y León en términos absolutos, con casi el doble de registros que Salamanca y casi cinco veces más que Soria. Su proporción relativa del 3,79% es además la segunda más alta en volumen significativo del grupo, lo que indica que el sector financiero no solo crece con la ciudad sino que lo hace a un ritmo ligeramente superior al resto de actividades. El heatmap es cualitativamente diferente al de todas las demás capitales: en lugar de uno o dos núcleos discretos, Valladolid muestra una mancha de alta densidad continua y extensa que cubre prácticamente todo el centro urbano consolidado, desde el eje Paseo de Zorrilla al sur hasta la Plaza de España al norte, con una intensidad sostenida que no decae bruscamente en los bordes sino que se difumina gradualmente. Esto refleja una ciudad que ha desarrollado un tejido financiero maduro y policéntrico, sin dependencia de un único eje bancario. Destaca especialmente la presencia de business_banking_service y business_brokers como categorías relevantes — un indicador claro de que Valladolid concentra banca corporativa y servicios de intermediación empresarial propios de una capital regional con sede de instituciones autonómicas, universidad técnica consolidada e industria de automoción. El median center se sitúa sobre el corazón del centro histórico comercial, pero dada la extensión de la mancha caliente, su poder discriminatorio es aquí menor que en ciudades más compactas — el verdadero valor analítico en Valladolid está en la extensión del heatmap, no en su pico.
Zamora — Centro histórico sólido, periferia por construir

Con 74 POIs financieros sobre 2.520 totales (2,93%) en un radio de 3 km, Zamora presenta la proporción relativa más baja de todo el grupo junto a León, lo que resulta especialmente significativo considerando que es una ciudad de tamaño similar a Ávila o Soria pero con una densidad financiera notablemente inferior. Este dato apunta a una economía local con menor actividad empresarial formal y mayor dependencia del sector primario y la administración pública, sectores que generan menos demanda de servicios financieros especializados. El heatmap muestra un patrón claramente asimétrico: un núcleo principal intenso y compacto sobre el centro histórico en torno a la Calle Santa Clara y la Plaza Mayor, y un lóbulo secundario hacia el sur en el barrio de Pinilla — el desarrollo residencial más activo de Zamora en las últimas décadas — de intensidad considerablemente menor. La separación entre ambos núcleos es limpia, sin gradiente continuo entre ellos, lo que sugiere que la banca en Pinilla responde exclusivamente a la demanda residencial local sin haber desarrollado aún una masa crítica de servicios corporativos o especializados. El median center se posiciona sobre el centro histórico pero ligeramente desplazado hacia el sur, traccionado por el peso de Pinilla. Destaca que con solo 74 registros, Zamora muestra todas las subcategorías financieras presentes en ciudades más grandes, incluyendo business_brokers y business_banking_service — lo que podría indicar cierta sobreestimación en la clasificación de Overture para esta ciudad, o bien la presencia de servicios orientados al sector agroindustrial zamorano que justifican esta tipología.
Conclusión
Este estudio sobre la distribución de POIs financieros en las nueve capitales de provincia de Castilla y León ha sido posible gracias a una combinación de herramientas enteramente abiertas y reproducibles.
El stack técnico (R, Shiny, DuckDB y Overture Maps) permite ejecutar el análisis completo en menos de un minuto por ciudad, consultando directamente los archivos GeoParquet almacenados en S3 sin necesidad de descargar ni almacenar datos localmente. El release utilizado data de apenas unos días (20260722) lo que garantiza que los datos reflejan el estado más reciente del dataset, una ventaja competitiva real respecto a fuentes estáticas que se actualizan anualmente o de forma irregular.

Cada POI incorpora en su tabla de atributos un campo sources_json que documenta su procedencia exacta: meta, microsoft, tomtom, osm o combinaciones de varias fuentes. Esta trazabilidad es fundamental para evaluar la fiabilidad de cada registro y para entender sesgos potenciales, por ejemplo, la cobertura de Meta tiende a ser más completa en establecimientos de hostelería y comercio, mientras que OSM aporta mayor precisión en equipamientos públicos y elementos urbanos estructurales.

Más allá de la visualización, la verdadera aportación analítica reside en el POIQ y en la matriz de correlaciones entre categorías. Que Deporte y Educación presenten correlaciones altas no es una casualidad (los equipamientos deportivos y los centros educativos comparten lógica de implantación: se sitúan en barrios residenciales consolidados con suelo disponible, alejados del centro comercial). Que Restauración y Alojamiento correlacionen fuertemente tampoco sorprende (ambos responden a la misma demanda turística y de negocios, co-localizándose en los mismos ejes urbanos). A todo ello se añade el campo confidence que Overture asigna a cada POI — un valor entre 0 y 1 que estima la probabilidad de que ese establecimiento exista realmente en esa ubicación — y que permite ponderar o filtrar los registros antes del análisis, descartando aquellos por debajo de un umbral de fiabilidad y garantizando que el POIQ se construye sobre datos contrastados y no sobre ruido. Estas correlaciones no son observaciones subjetivas: son medidas estadísticas reproducibles que permiten comparar ciudades, detectar anomalías y fundamentar decisiones de inversión o planificación con base científica.
Frente a los rankings cualitativos o los informes de percepción, la cuantificación espacial apoyada en open data ofrece algo diferente: equilibrio territorial medible, comparable y auditable. Todas las ciudades analizadas con el mismo método, el mismo radio, la misma fecha, la misma escala y los mismos criterios. Eso es lo que convierte un mapa bonito en una herramienta de política pública o de estrategia empresarial.
Análisis realizado con assetIQ · R · DuckDB · Overture Maps release 20260722.0 · Geovisualization.net
Alberto Concejal
Analista GIS
https://geovisualization.net/
fuentes:
Overture Maps Foundation — Places dataset, release 2026-05-20 · overturemaps.org DuckDB + httpfs extension — Serverless querying of remote Parquet files · duckdb.org R Project & Shiny — Statistical computing and interactive web applications · r-project.org · shiny.posit.co OpenStreetMap contributors — Base cartography via Stadia Maps / OpenMapTiles · openstreetmap.org Esri World Imagery — Satellite basemap · esri.com assetIQ · Geovisualization.net — Spatial POI intelligence tool · geovisualization.net