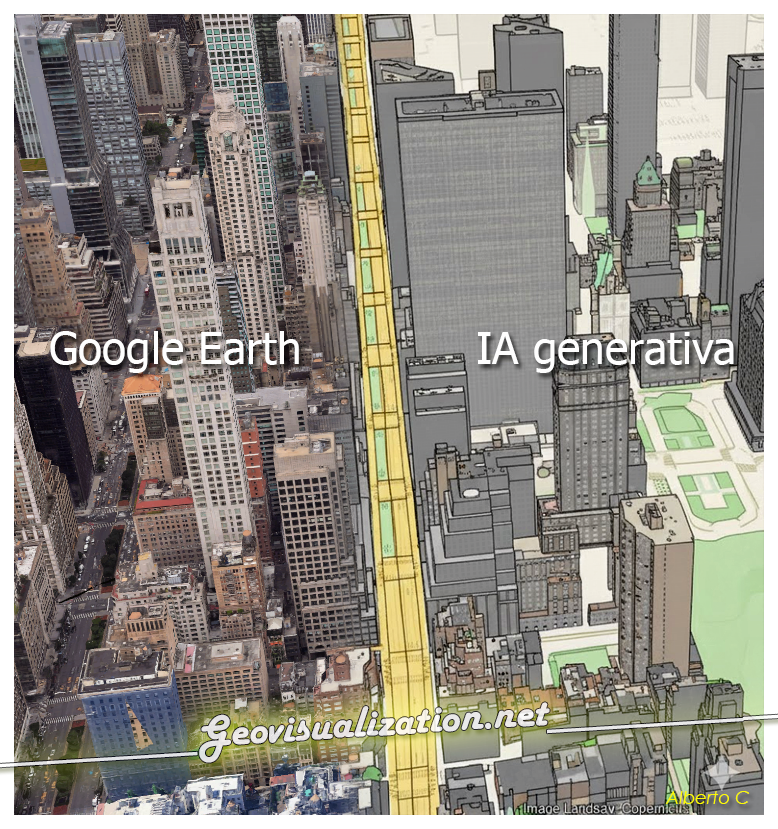
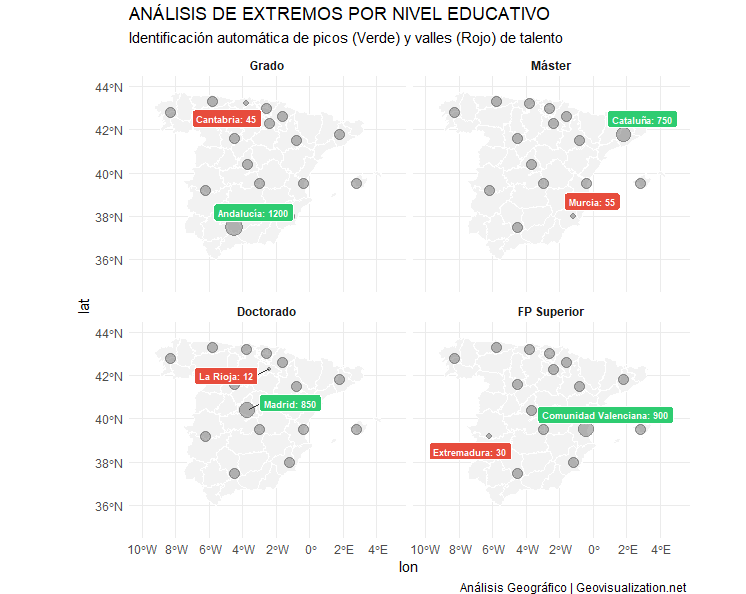
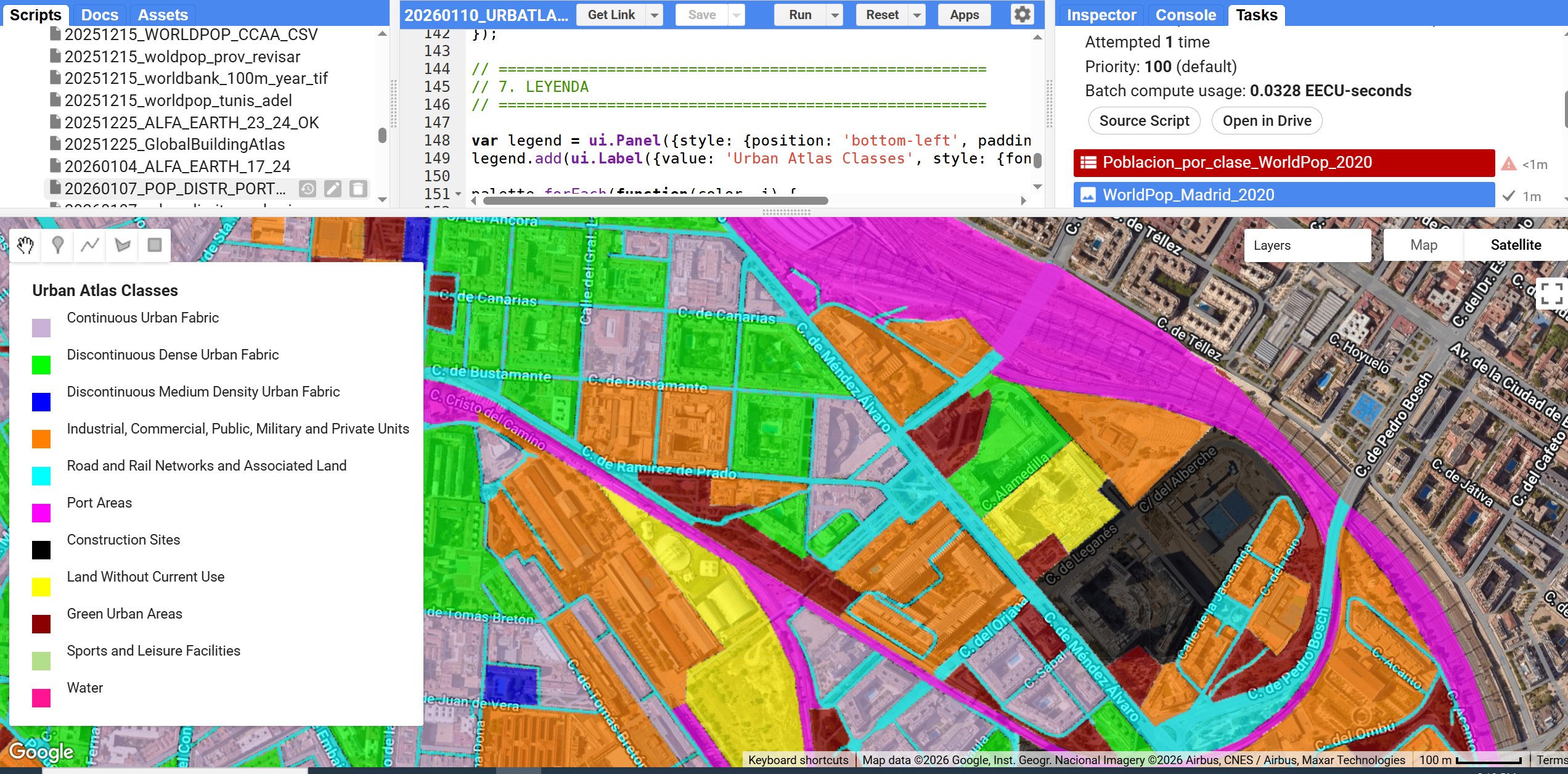
¿Alguna vez has querido visualizar el relieve de un territorio en 3D directamente desde RStudio, sin depender de software GIS externo? Mapterhorn es un proyecto open source que distribuye modelos digitales de elevación (MDT) de alta resolución — hasta 2 metros en España — empaquetados en formato PMTiles, un estándar moderno que permite servir datos geoespaciales sin necesidad de un servidor propio.
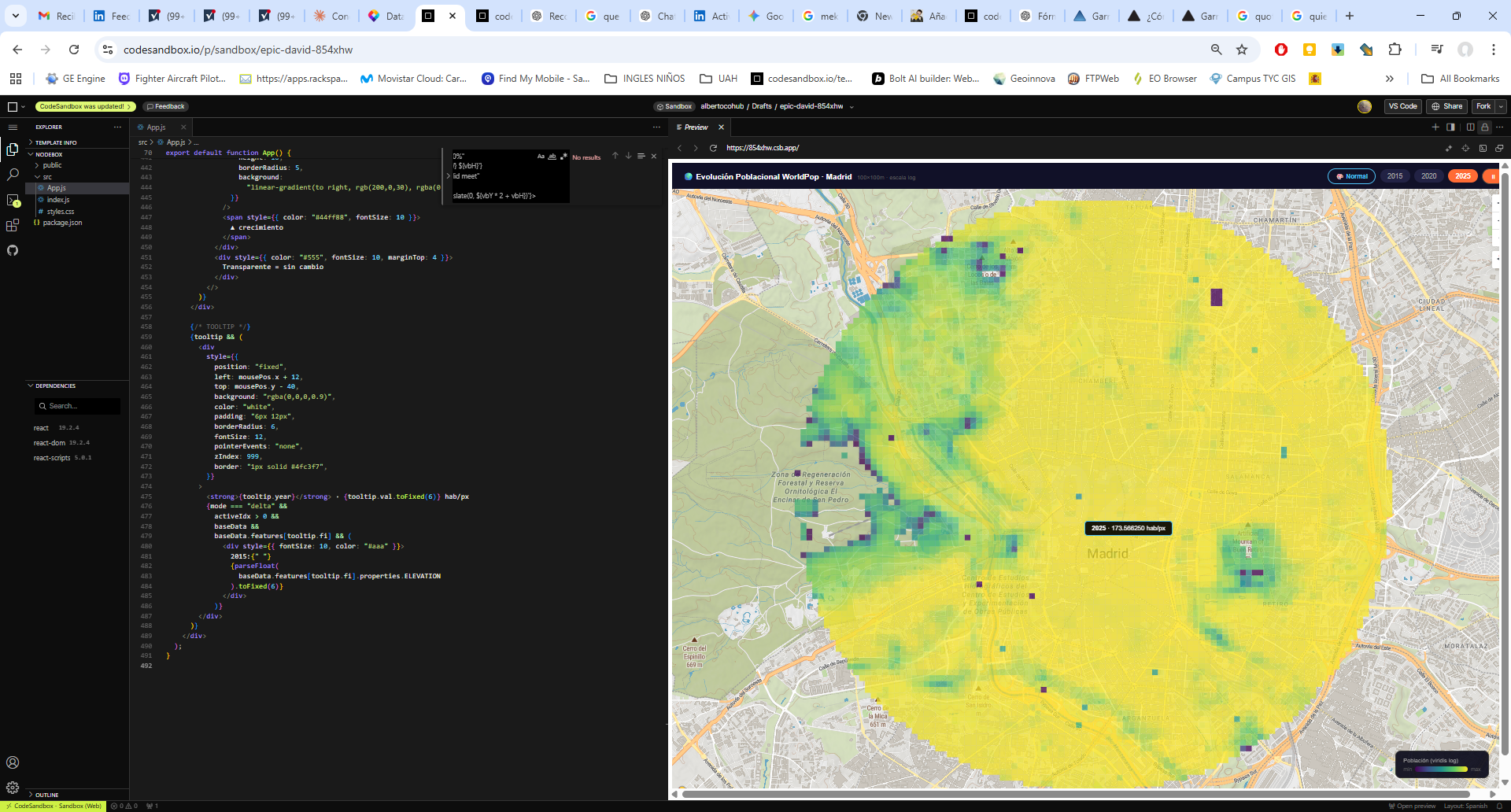
En este post veremos cómo configurar Mapterhorn en R usando el paquete mapgl en Rstudio, que nos permite crear mapas interactivos con terreno 3D en pocas líneas de código. El resultado: visualizaciones como la que ves abajo, con sombreado de relieve (hillshade) generado directamente desde los datos de elevación del IGN.
No necesitas experiencia previa en cartografía — si sabes instalar paquetes en R, puedes seguir este tutorial.

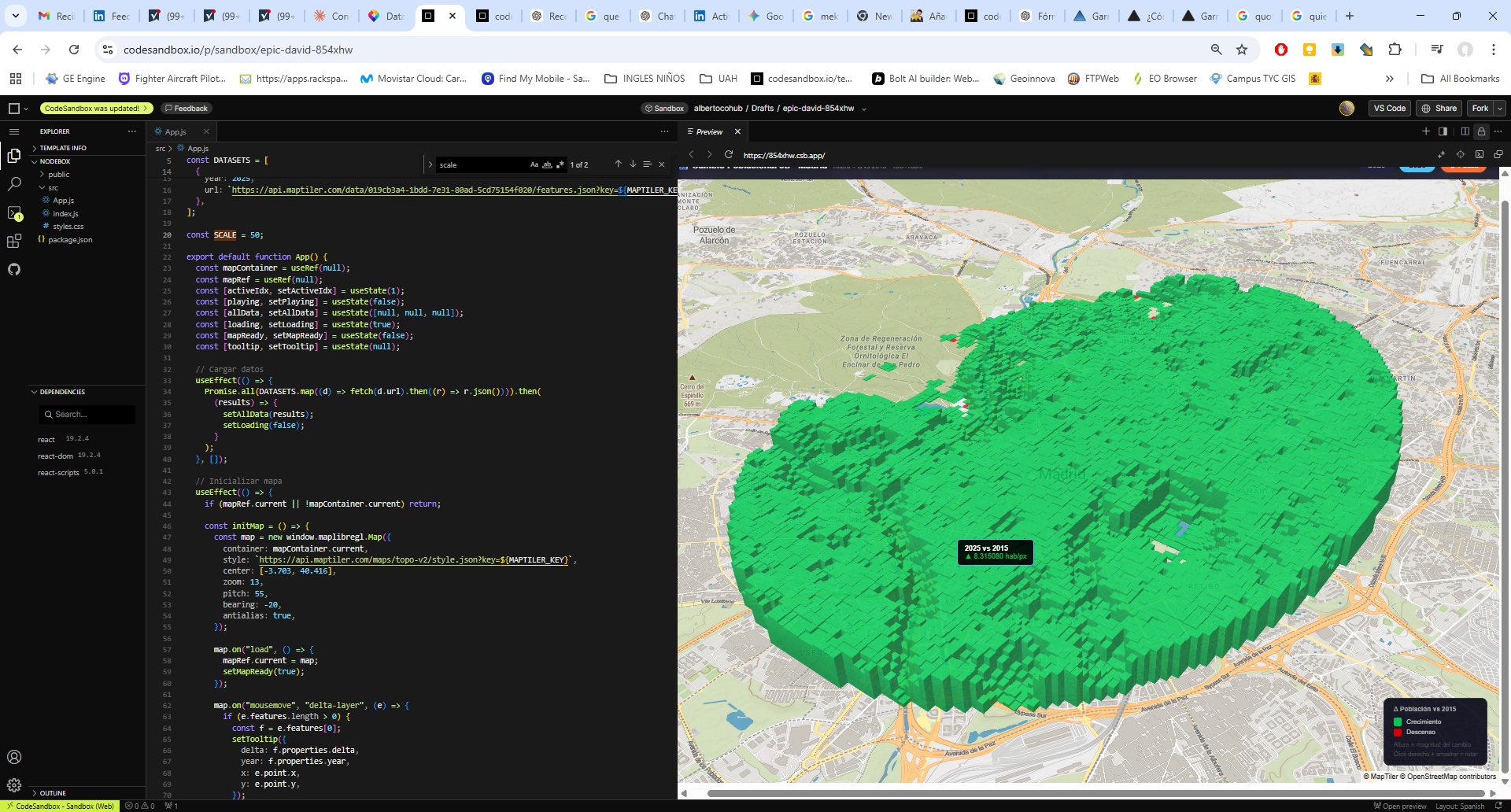
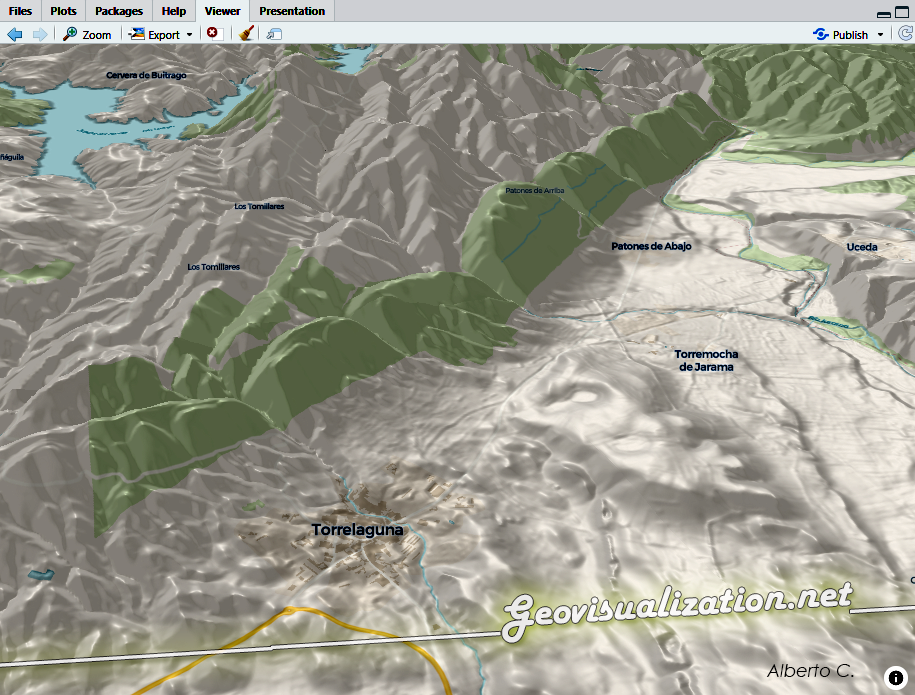
El siguiente paso es combinar el terreno de Mapterhorn con un estilo cartográfico que aporte contexto geográfico. En este ejemplo vemos la Sierra Norte de Madrid — con el embalse de Bustarviejo al fondo y municipios como Torrelaguna en primer plano — renderizada con una inclinación de cámara (pitch) de 60° y exageración de relieve moderada.
install.packages(c("mapgl", "terra", "elevatr", "sf", "tidyterra", "ggplot2"))---------------------------------library(mapgl)library(terra)library(elevatr)library(sf)maplibre( style = carto_style("voyager"), center = c(-3.703, 40.416), zoom = 14, pitch = 40) |> add_raster_dem_source( id = "mapterhorn_pro", url = "pmtiles://https://download.mapterhorn.com/planet.pmtiles", tileSize = 512, encoding = "terrarium" ) |> set_terrain(source = "mapterhorn_pro", exaggeration = 0.1) |> add_layer( id = "sombras", type = "hillshade", source = "mapterhorn_pro", paint = list( "hillshade-exaggeration" = 0.5, "hillshade-shadow-color" = "#333333", "hillshade-illumination-direction" = 315 ) )
El resultado es un mapa donde el relieve deja de ser un dato abstracto y se convierte en algo inmediatamente legible: puedes ver de un vistazo la diferencia de altitud entre el fondo del valle del Jarama y las cumbres de la sierra, algo que un mapa plano convencional no transmite con la misma fuerza.
library(mapgl)maplibre( style = carto_style("voyager"), center = c(-3.60, 40.75), zoom = 11, pitch = 60) |> add_raster_dem_source( id = "mapterhorn", url = "pmtiles://https://download.mapterhorn.com/planet.pmtiles", tileSize = 512, encoding = "terrarium" ) |> set_terrain(source = "mapterhorn", exaggeration = 1.5)
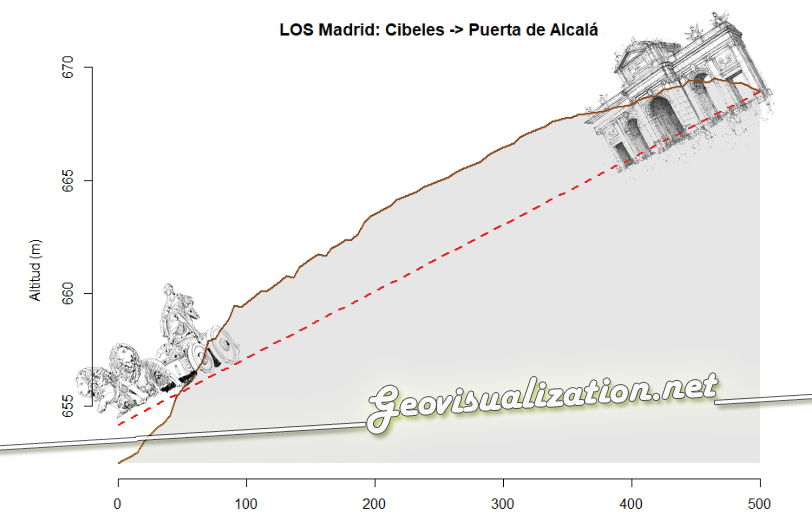
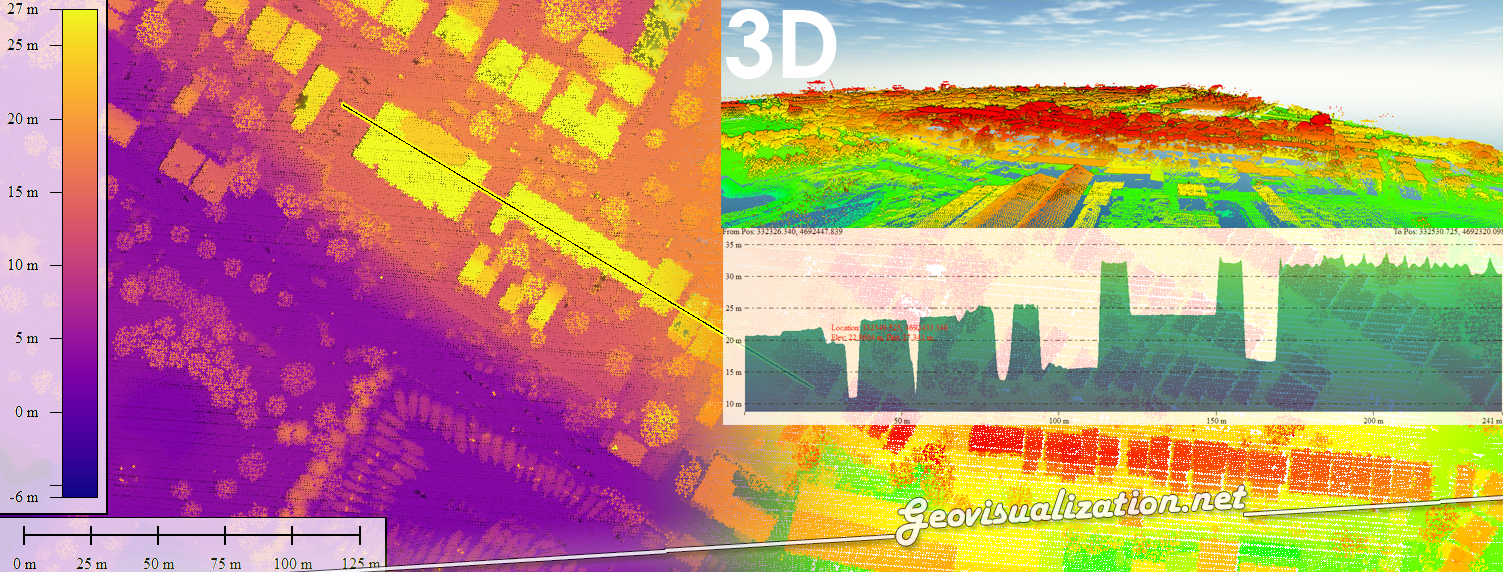
Análisis de visibilidad: ¿se ven Cibeles y la Puerta de Alcalá entre sí?
Más allá de la visualización estética, los datos de elevación de Mapterhorn permiten hacer análisis geoespaciales reales. Un ejemplo clásico es el análisis de línea de visión (Line of Sight, LOS): dado un observador en un punto A, ¿puede ver el punto B sin que el terreno lo obstaculice?
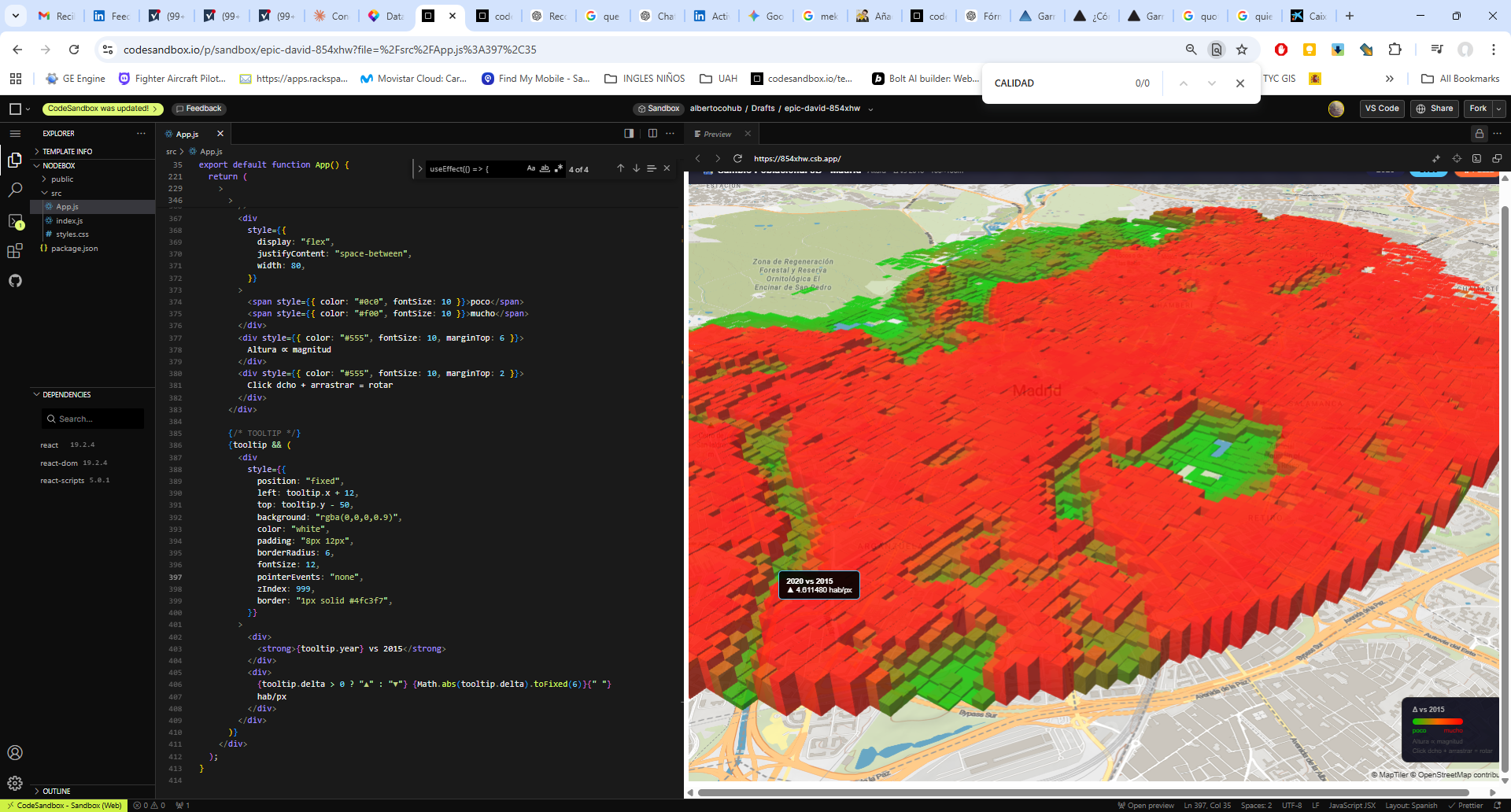
En este caso trazamos el perfil de elevación entre la Fuente de Cibeles y la Puerta de Alcalá — apenas 500 metros de distancia en el centro de Madrid. La línea marrón representa el terreno real; la línea roja discontinua es la línea de visión teórica desde los ojos del observador (a 1,70 m de altura, ten en cuenta que la escala del eje Y está magnificada para mejor comprensión).
El resultado es claro: el terreno queda por encima de la línea de visión en todo el trayecto, lo que indica que el suelo sube progresivamente desde Cibeles hacia Alcalá. Curiosamente, aunque ambos monumentos son perfectamente visibles entre sí en la realidad (la calle es recta y despejada), el propio desnivel del terreno hace que la línea de visión rasante quede por debajo del suelo si no se tienen en cuenta los edificios ni la altura real de los monumentos.
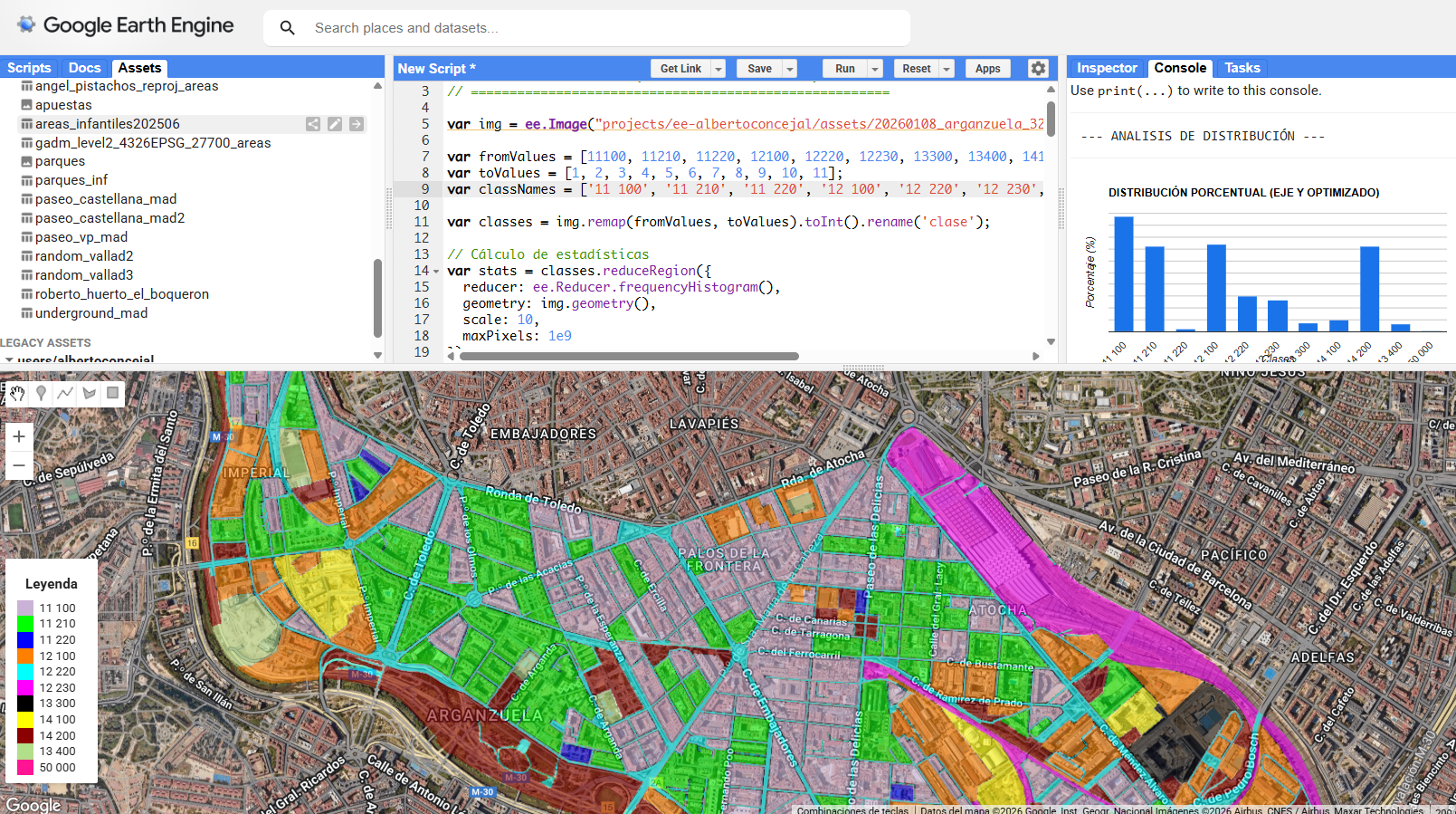
Ahora comparemos nuestro Mapterhorn 2m con el Copernicus 30m, a pesar de que esta comparación es inconsistente más allá de una interpretación puramente visual.
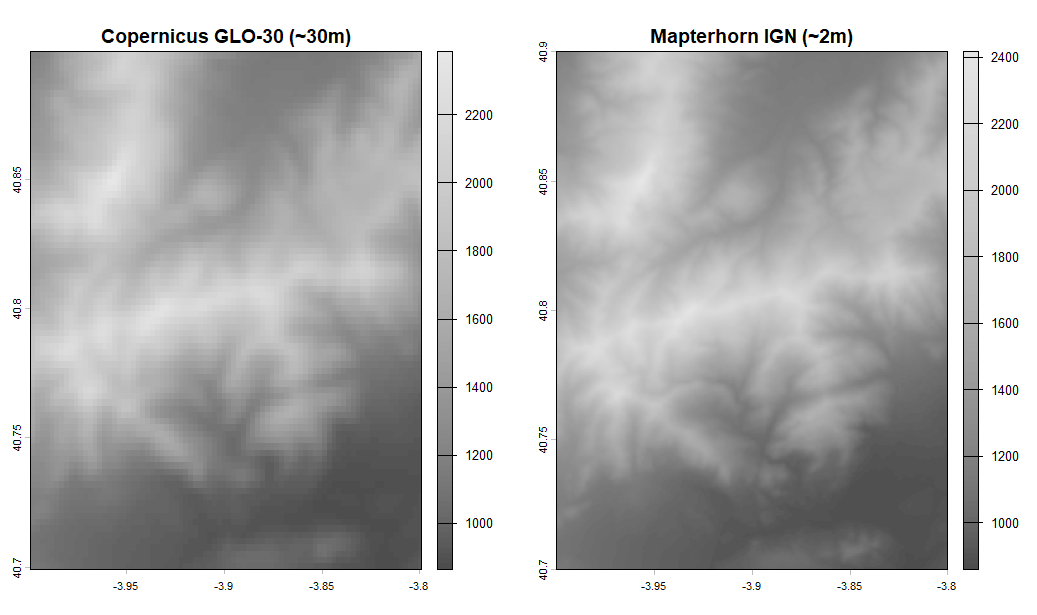
library(elevatr)library(terra)library(ggplot2)# 1. Zona y descarga de ambos MDTspuntos <- data.frame(x = c(-4.0, -3.8), y = c(40.7, 40.9))dem_low <- rast(get_elev_raster(puntos, z = 8, prj = "EPSG:4326", clip = "bbox"))dem_high <- rast(get_elev_raster(puntos, z = 14, prj = "EPSG:4326", clip = "bbox"))# 2. Perfil de elevación (path profile) a lo largo de una transectapasos <- 200lon_seq <- seq(-4.0, -3.8, length.out = pasos)lat_seq <- seq(40.7, 40.9, length.out = pasos)coords <- cbind(lon_seq, lat_seq)z_low <- extract(dem_low, coords)[, 1]z_high <- extract(dem_high, coords)[, 1]dist_m <- seq(0, 25000, length.out = pasos) # ~25km de transecta# 3. Path profile comparativoperfil_df <- data.frame( distancia = rep(dist_m, 2), elevacion = c(z_low, z_high), fuente = rep(c("Copernicus GLO-30 (~30m)", "Mapterhorn IGN (~2m)"), each = pasos))ggplot(perfil_df, aes(x = distancia / 1000, y = elevacion, color = fuente)) + geom_line(linewidth = 0.8, alpha = 0.85) + scale_color_manual(values = c("Copernicus GLO-30 (~30m)" = "#e74c3c", "Mapterhorn IGN (~2m)" = "#2c3e50")) + labs( title = "Perfil de elevación: Copernicus vs Mapterhorn", subtitle = "Transecta SW-NE sobre la Sierra de Guadarrama", x = "Distancia (km)", y = "Altitud (m)", color = NULL ) + theme_minimal(base_size = 13) + theme(legend.position = "top")# 4. RMSE — remuestrea el MDT de alta res a la resolución del bajodem_high_resampled <- resample(dem_high, dem_low, method = "bilinear")z_low_full <- values(dem_low)z_high_full <- values(dem_high_resampled)# Elimina NAsidx <- complete.cases(z_low_full, z_high_full)rmse <- sqrt(mean((z_high_full[idx] - z_low_full[idx])^2))cat(sprintf("RMSE entre Copernicus GLO-30 y Mapterhorn IGN: %.2f metros\n", rmse))# 5. Diferencia espacial (mapa de error)diff_raster <- dem_high_resampled - dem_lowplot(diff_raster, main = "Diferencia de elevación: Mapterhorn - Copernicus (m)", col = hcl.colors(100, "RdBu", rev = TRUE))
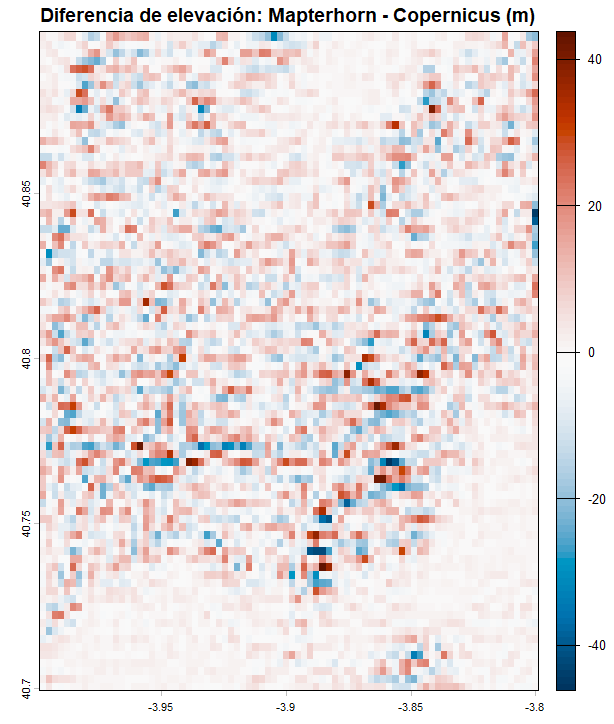
Pero como avanzaba, Copernicus GLO-30 y Mapterhorn IGN no son dos mediciones del mismo fenómeno a distinta resolución — son dos productos con orígenes, metodologías y fechas de captura completamente diferentes. Copernicus GLO-30 se deriva del radar de apertura sintética del satélite TanDEM-X, que mide la superficie de la Tierra desde el espacio con una resolución nominal de 30 metros. Al ser una medición radar, captura la parte superior de la vegetación y los edificios, no el suelo desnudo — lo que en cartografía se llama un Modelo Digital de Superficie (MDS), no un Modelo Digital del Terreno (MDT) estricto.
Mapterhorn distribuye los datos del IGN España, obtenidos mediante vuelos LiDAR que permiten filtrar la vegetación y los edificios para obtener el suelo real. El resultado es un MDT de 2 metros de resolución que representa la topografía con una precisión altimétrica muy superior.
Por tanto, el RMSE que calculamos no mide únicamente el error de Copernicus — mide la diferencia acumulada entre dos modelos distintos, que incluye diferencias reales de resolución, diferencias metodológicas y el efecto de la vegetación sobre el radar. En zonas boscosas como la sierra de Guadarrama, estas diferencias pueden ser especialmente pronunciadas, llegando a varios metros en las áreas más densamente arboladas.

Lo que hemos visto en este post es solo el punto de entrada. Una vez que tienes los datos de elevación conectados, las posibilidades se multiplican rápidamente.
En el ámbito del análisis de terreno puedes calcular pendientes y orientaciones para estudios de riesgo de erosión, planificación de infraestructuras o modelado de radiación solar. A partir del mismo MDT puedes delimitar cuencas hidrográficas automáticamente, trazar la red de drenaje teórica o calcular el área de captación de cualquier punto del territorio. Para proyectos de energía renovable, cruzar las orientaciones de ladera con datos de irradiación permite identificar zonas óptimas para instalaciones solares con pocas líneas de código.
En visualización avanzada puedes combinar el terreno 3D con cualquier capa vectorial propia — rutas de senderismo, límites administrativos, localizaciones de campo — y exportar el resultado como HTML interactivo para publicar directamente en la web. El paquete mapgl permite animar la cámara con fly_to() para crear recorridos virtuales sobre el terreno, algo especialmente útil para presentaciones o divulgación. También puedes generar mapas de sombreado artístico cambiando el ángulo de iluminación para conseguir efectos visuales dignos de cartografía profesional.
Para aplicaciones más especializadas, los datos de Mapterhorn son la base ideal para análisis de intervisibilidad a escala regional — por ejemplo, calcular desde cuántos puntos del territorio es visible una antena, un parque eólico o una torre de vigilancia de incendios. En urbanismo y ordenación del territorio permiten modelar el impacto visual de nuevas construcciones o calcular perfiles de ruido considerando la topografía real.
Todo esto sin salir de RStudio, sin licencias de software GIS y con datos de la máxima resolución disponible para España.
Mapterhorn ha eliminado uno de los principales obstáculos que tenían los usuarios de R para trabajar con datos de elevación de alta resolución: la complejidad de acceder, descargar y procesar MDTs de fuentes institucionales. Con una sola URL y tres líneas de código tienes acceso a los mejores datos topográficos disponibles para España y buena parte de Europa, listos para visualizar o analizar.
Espero que te haya interesado,
Alberto C.
GIS Analyst
#RStats #Mapterhorn #GIS #Cartografía #MapGL #TerrainAnalysis #OpenData #Geovisualización #RStudio #LiDAR #IGN #SpatialData #Mapping #DataViz #Topografía #RemoteSensing #OpenSource #GeospatialR #MDT #Hillshade
https://mapterhorn.com/
https://protomaps.com/blog/mapterhorn-terrain/
https://github.com/mapterhorn
https://posit.co/download/rstudio-desktop/
https://centrodedescargas.cnig.es/