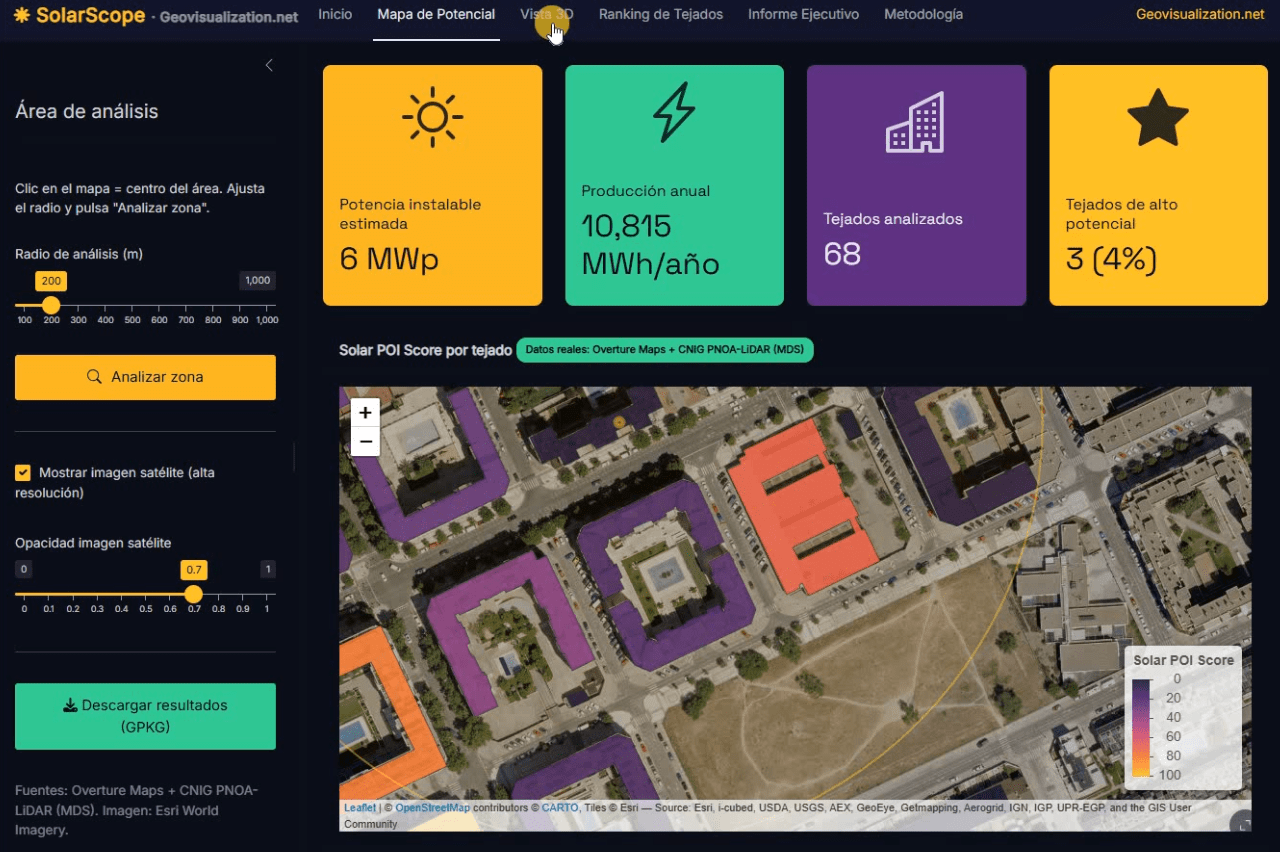
Llevo unos días dándole vueltas a una idea que, en el fondo, es bastante sencilla: si tenemos la huella de cada edificio, su altura y un modelo digital de superficies de alta resolución, ¿por qué seguimos viendo estudios de potencial solar que tratan los tejados como manchas homogéneas sobre un mapa? De esa pregunta, y de unas cuantas sesiones intensas de R, ha salido SolarScope, una aplicación Shiny que estoy desarrollando para hacer scoring de potencial fotovoltaico tejado a tejado, con datos abiertos y un flujo que se puede reproducir tanto en España como en cualquier sitio del mundo donde pueda conectarme a un DSM de alta resolución!
La motivación es doble. Por un lado, profesional: vengo de quince años moviéndome entre geografía, teledetección y GIS aplicado, y cada vez que he tocado proyectos de energía solar he visto el mismo cuello de botella. Los modelos de potencial suelen apoyarse en rásteres de baja resolución (SRTM, Copernicus DEM a 30 m) que son perfectamente válidos para planificación territorial a gran escala, pero que se quedan cortos en cuanto entras en el detalle de una nave industrial o un polígono residencial: ahí lo que importa es la sombra que proyecta el edificio de al lado, la orientación real de la cubierta y cuántos metros cuadrados aprovechables tiene cada tejado después de descontar lucernarios, antenas y pasillos técnicos. Por otro lado, hay una motivación más simple: tenía ganas de construir algo vistoso, con mapas 3D, que sirviera como pieza de presentación ante empresas del sector —y de paso, demostrar que con herramientas open source se puede llegar muy lejos sin depender de licencias de software propietario.
De dónde vienen los datos
El corazón de SolarScope es la combinación de tres fuentes. La primera es Overture Maps, el proyecto colaborativo (Meta, Microsoft, Amazon, TomTom y otros) que publica footprints de edificios a escala global con atributos de altura y número de plantas, distribuidos como Parquet sobre S3. Aquí es donde DuckDB se convierte en la pieza más elegante del stack: con la extensión httpfs y spatial, puedo lanzar una consulta SQL directamente contra los ficheros remotos, filtrar por bounding box usando los campos bbox.xmin/xmax/ymin/ymax y traerme solo los edificios que caen dentro del área de interés, sin descargar nada de más. Cuando la altura no está disponible —que pasa más a menudo de lo que gustaría— caigo en una estimación a partir del número de plantas, y si tampoco hay eso, asumo una nave de una planta. No es perfecto, pero es razonable para naves industriales, que es justo el tipo de cubierta que más interesa a un desarrollador solar.
https://albertogis.shinyapps.io/SolarScope
La segunda fuente es el Modelo Digital de Superficies (MDS) del vuelo LiDAR del PNOA, servido por el CNIG a través de un servicio WCS. Aquí sí que tuve que arremangarme: el endpoint correcto no es el de siempre (el del MDT del IGN), sino wcs-mds.idee.es/mds, y el identificador de cobertura tampoco sigue la convención que uno esperaría —nada de Elevacion25830_5, sino simplemente mds05—. Una vez resuelto eso (y la consabida reproyección de EPSG:4326 a EPSG:25830, porque el servicio trabaja en metros UTM, no en grados), el DSM permite calcular, para cada edificio, si hay construcciones vecinas más altas que le proyecten sombra, y con eso derivar un factor de sombreado real en lugar de uno inventado. Para Estados Unidos, el equivalente es USGS 3DEP, que ofrece DSM de hasta 1 metro de resolución allá donde hay cobertura LiDAR —el conector está escrito y solo pendiente de pruebas con datos reales, pero la arquitectura ya contempla ambos países sin tocar el resto de la aplicación.
La tercera pieza es, simplemente, la geometría de cada footprint: a partir de la relación de aspecto del bounding box estimo un factor de orientación, asumiendo que la mayoría de cubiertas industriales son planas (donde la orientación pesa poco) pero penalizando ligeramente las naves muy alargadas en sentido norte-sur frente a las que se extienden este-oeste, que en el hemisferio norte “miran” más al sur.
El cálculo: del tejado al kWp
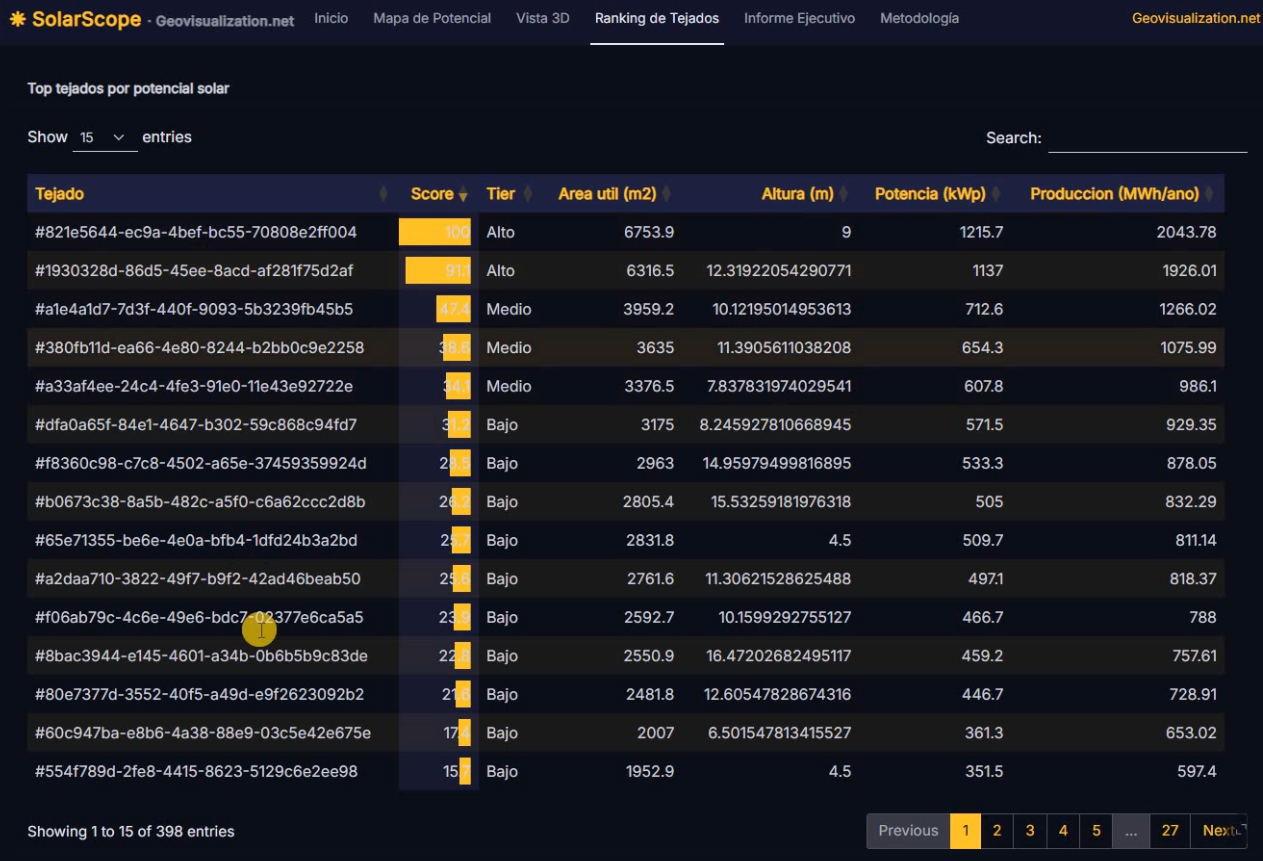
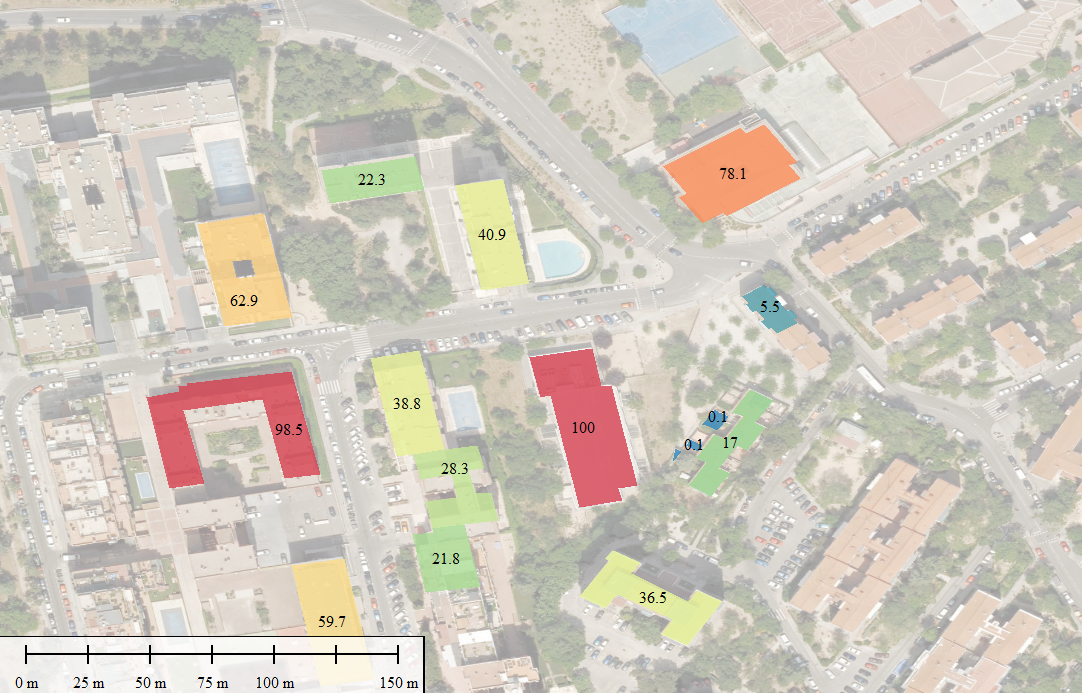
Con esos tres ingredientes —área, altura, orientación y sombreado—, el motor de scoring aplica un modelo bastante directo inspirado en los valores de referencia de PVGIS: irradiación global horizontal anual (en torno a 1.650 kWh/m²/año para Madrid), un porcentaje de área útil tras descontar elementos técnicos, una eficiencia de sistema fotovoltaico del 20% y una densidad de potencia instalable de 0,18 kWp por metro cuadrado útil. El resultado es, para cada edificio, una potencia instalable en kWp, una producción anual estimada en MWh y un Solar POI Score normalizado de 0 a 100 que combina producción total con superficie disponible —porque un tejado grande y mediocre puede ser más interesante para un desarrollador que uno pequeño y perfecto—. Los tejados se clasifican en tres niveles (bajo, medio, alto), lo que permite, de un vistazo, identificar qué activos merecen una visita técnica.
La aplicación: de la idea al mapa interactivo
Todo esto vive dentro de una app Shiny con un diseño oscuro deliberadamente “de producto”, construido sobre bslib con tipografías Inter y Space Grotesk, y una paleta que va del morado profundo al amarillo solar —la misma que reaparece en cada gráfico, en la leyenda del mapa y, por qué no, en la portada de la propia aplicación, donde un skyline de edificios generado en SVG (con sus correspondientes “sombreros” de colores en cada tejado) hace de fondo desenfocado tras el logo.
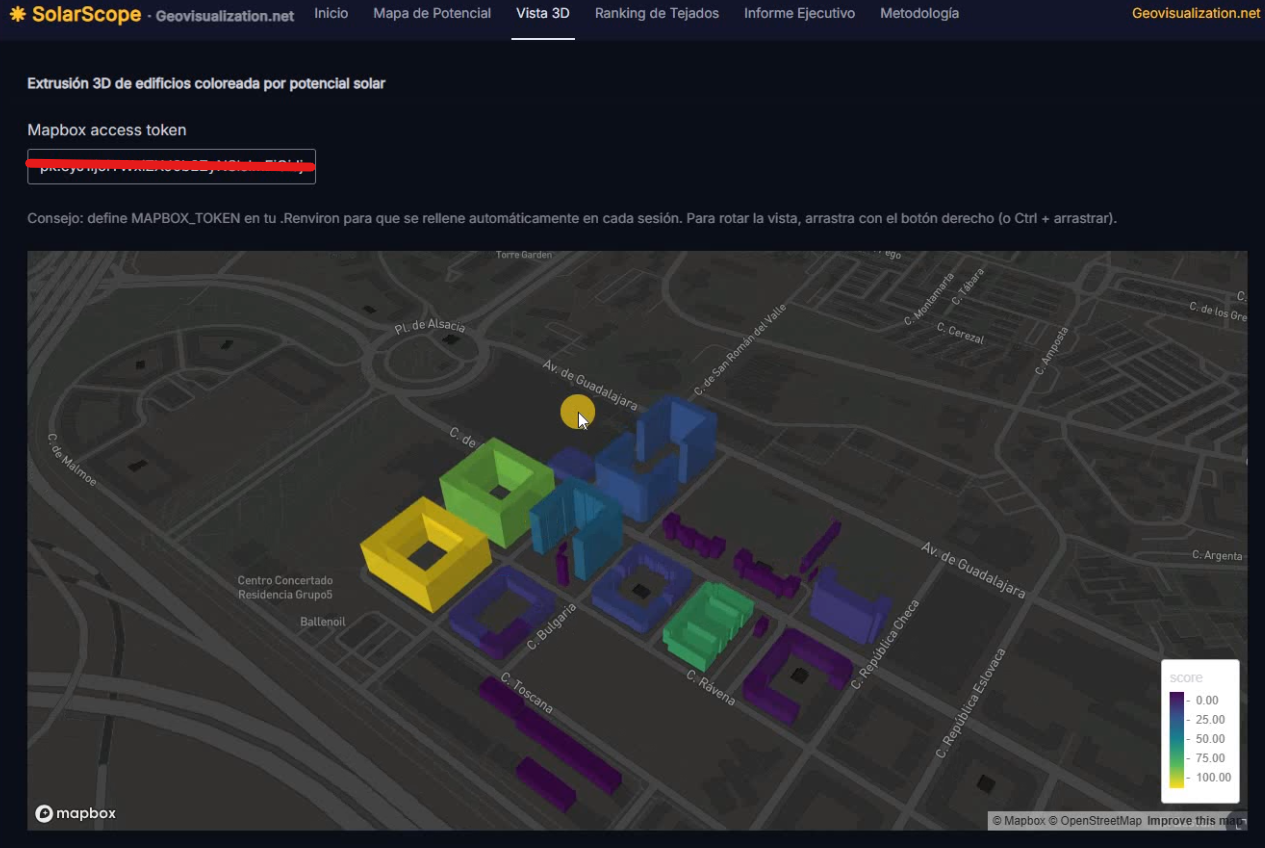
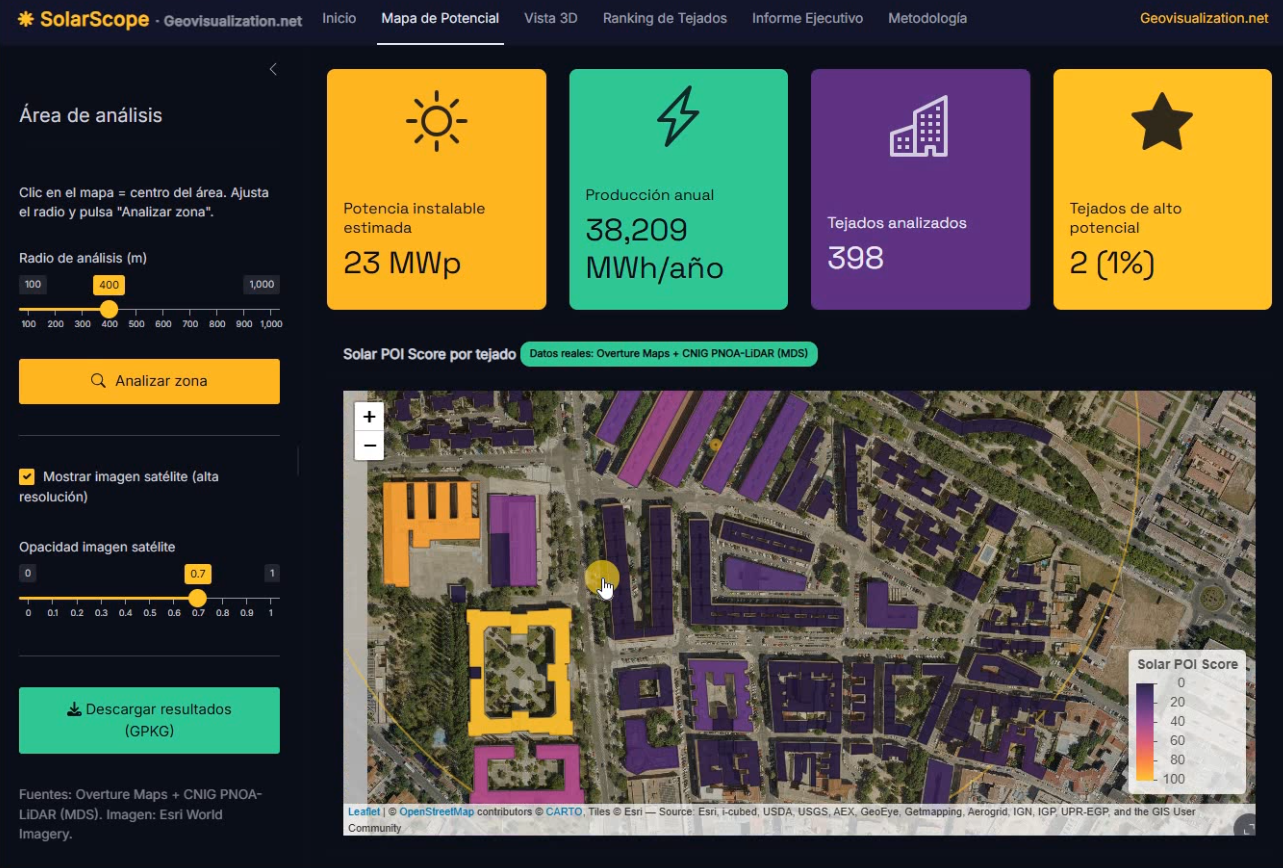
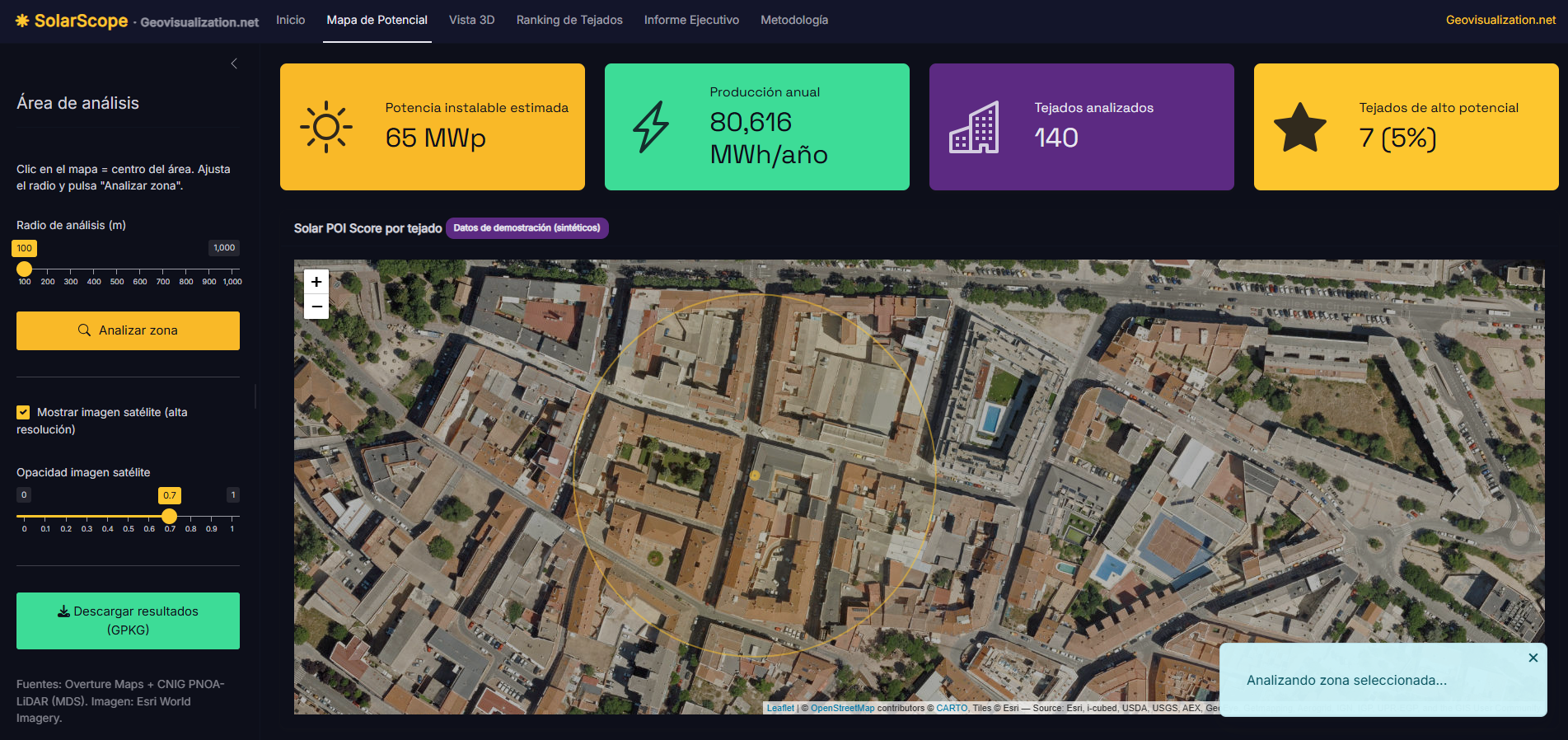
La interacción es deliberadamente simple: el usuario hace clic en el mapa para fijar un punto central, ajusta con un slider el radio de análisis —entre 100 y 1.000 metros— y pulsa “Analizar zona”. En ese momento, la app reconstruye el bounding box, relanza las consultas a Overture y al MDS del CNIG, recalcula todas las métricas y redibuja tanto el mapa 2D (con CartoDB Dark Matter como base) como una vista 3D con extrusión de edificios por altura y coloreada por score, esta última construida con mapdeck, que en el fondo es un envoltorio de deck.gl sobre Mapbox GL. Si el conector de datos reales falla por cualquier motivo —sin conexión, cambio de release de Overture, servicio del CNIG caído—, la app cae automáticamente a un generador de datos sintéticos con la misma estructura, y lo indica con un discreto badge de color para que nunca te quedes con una pantalla en blanco en mitad de una demo. Para quien necesite explotar los resultados fuera de la app, hay un botón de exportación a GeoPackage con todos los atributos calculados, y otro que genera un informe ejecutivo en HTML autocontenido —mapa, KPIs y ranking incluidos— listo para enviar por correo.
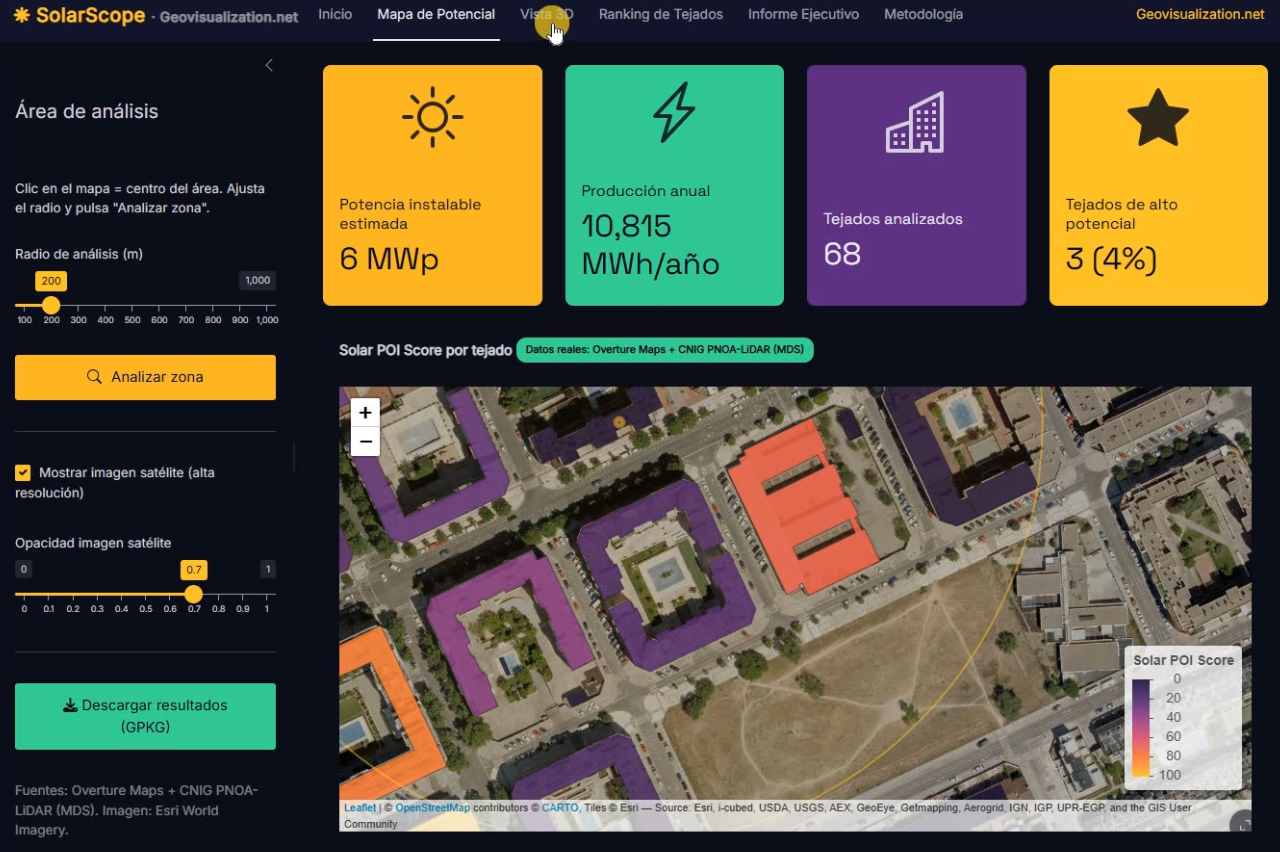
Como guiño visual adicional, y porque a veces lo más vistoso no tiene por qué ser lo más complejo, incorporé también una capa opcional de imagen de alta resolución (Esri World Imagery) con control de opacidad sobre el mapa base oscuro: sirve únicamente para contextualizar visualmente la zona —el cálculo de sombreado sigue apoyándose en el DSM del CNIG—, pero al venir servida como teselas por CDN carga muchísimo más rápido que el WMS del PNOA, que para un uso puramente visual resultaba innecesariamente pesado.
El stack, en una frase
Si tuviera que resumir la pila tecnológica en un párrafo: R y Shiny como columna vertebral, bslib y CSS personalizado para la interfaz, sf y terra para todo lo geoespacial vectorial y ráster, DuckDB con httpfs/spatial como motor de consulta sobre datos en la nube sin descargas intermedias, leaflet para el mapa 2D y mapdeck para la vista 3D, DT para las tablas interactivas y rmarkdown para los informes ejecutivos. Todo open source, todo reproducible, y todo pensado para que el mismo esqueleto sirva tanto para un polígono industrial en Vicálvaro como, cambiando el conector de DSM, para un parque empresarial en Arizona.
Para quién es esto
El público natural son desarrolladores y operadores de energía solar que necesitan priorizar carteras de tejados —ya sea para autoconsumo industrial, comunidades energéticas o grandes cubiertas logísticas— sin tener que encargar un estudio LiDAR específico cada vez que aparece una oportunidad. También tiene sentido para consultoras de sostenibilidad que necesiten estimar potencial fotovoltaico como parte de informes ESG, para administraciones locales que quieran mapear el potencial solar de sus polígonos industriales, o simplemente para cualquier estudio de GIS que quiera mostrar que el análisis espacial de alta resolución no tiene por qué vivir solo dentro de un escritorio ArcGIS. Y sí, en estos días concretos la estoy preparando como pieza de demostración para una conversación con una empresa del sector solar —si sale adelante, ya contaré más por aquí.
Como suele pasar en este oficio, la parte más “glamurosa” —el mapa 3D girando con la cámara, los colores del score, la portada con el skyline desenfocado— es la que menos tiempo me ha llevado. Lo que de verdad ha consumido las horas ha sido, cómo no, encontrar el COVERAGEID correcto de un servicio WCS y pelearme con la codificación de caracteres en una consola de R en Windows: si alguna vez os preguntáis por qué los geógrafos envejecemos mal, no es por el sol de las salidas de campo, es por los acentos UTF-8 dentro de backticks de R. Reproject responsibly.
Iré documentando en este blog los siguientes pasos: cerrar el conector de Estados Unidos con USGS 3DEP, refinar la orientación de cubierta con geometría de fachadas reales, y —si el tiempo lo permite— un modelo de sombreado hora a hora basado en la posición solar real a lo largo del año.

Si todo va bien, la próxima entrada debería poder escribirse en mucho menos tiempo que esta: la idea es que cada iteración de SolarScope deje el terreno un poco más allanado para la siguiente.
Espero que os haya interesado!
Alberto Concejal
Geospatial Analyst
