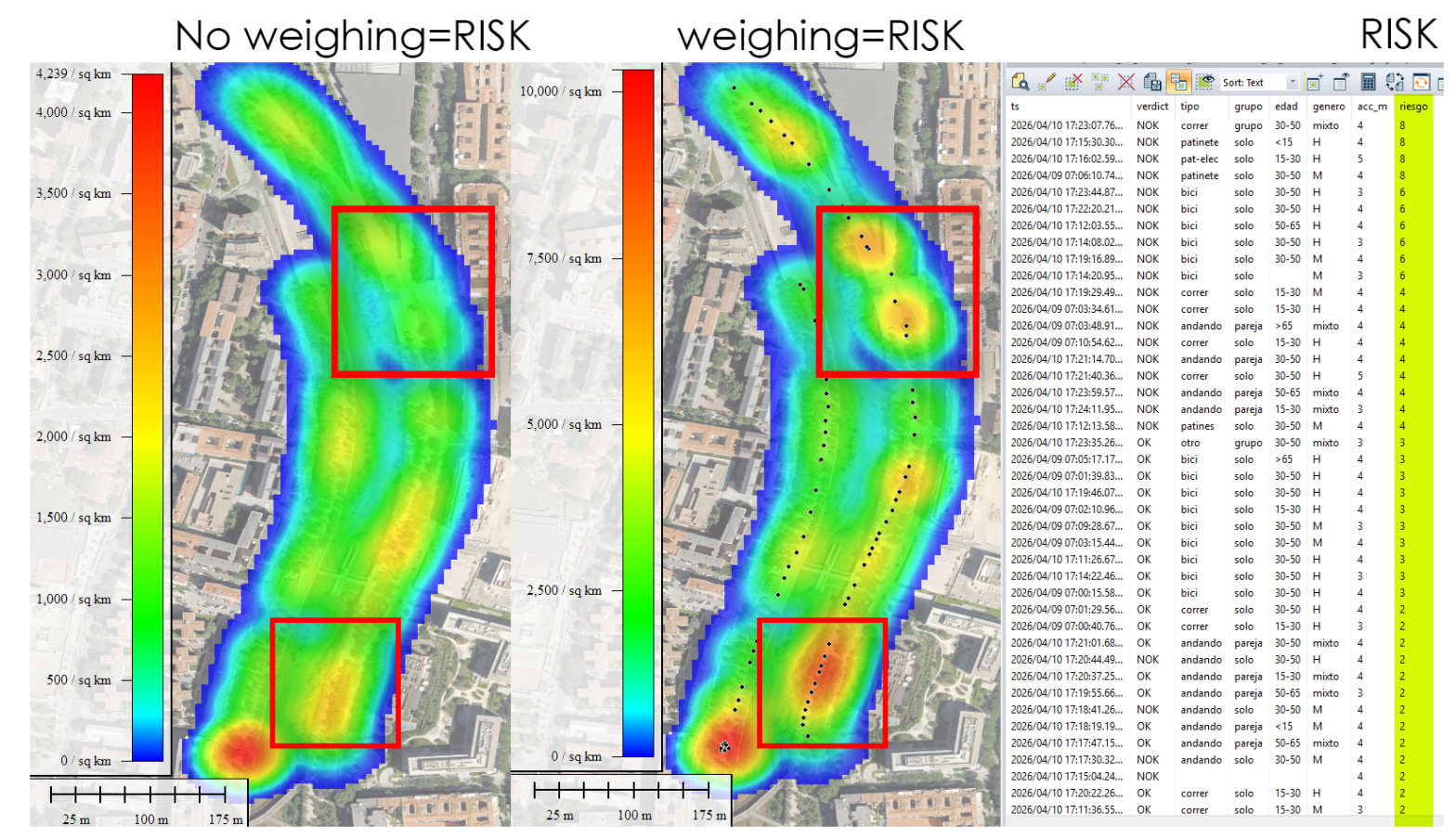
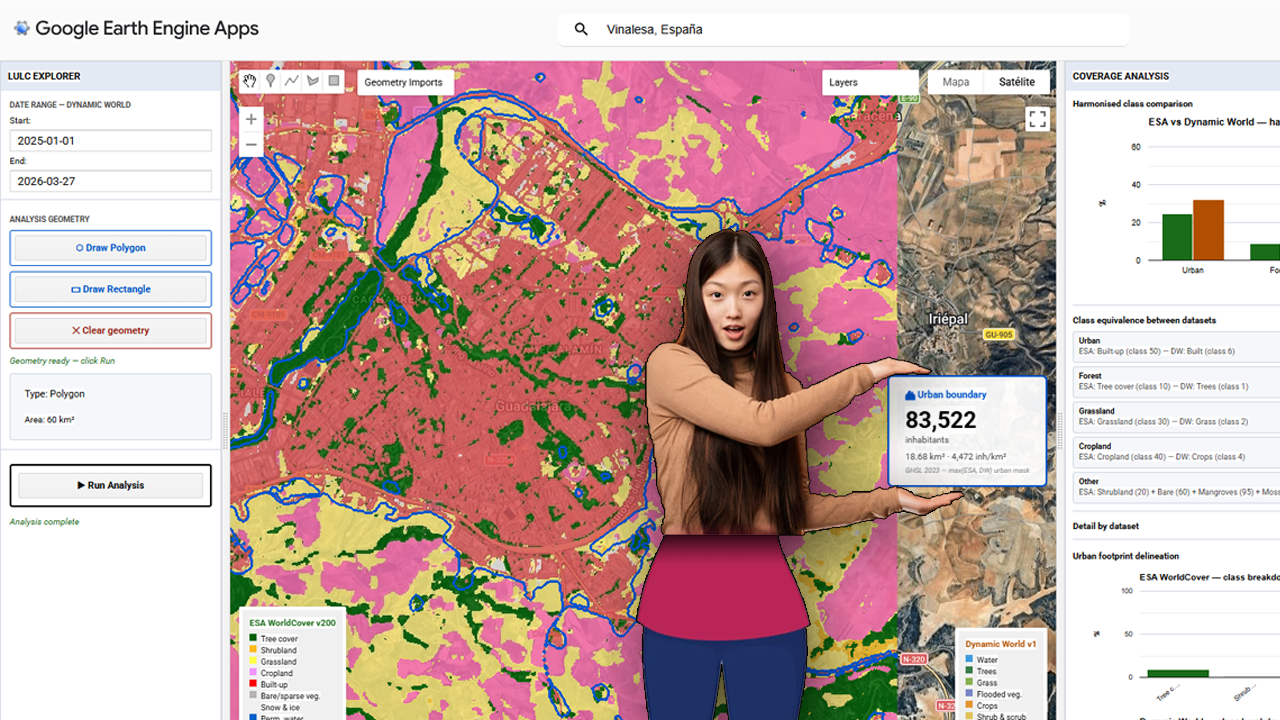
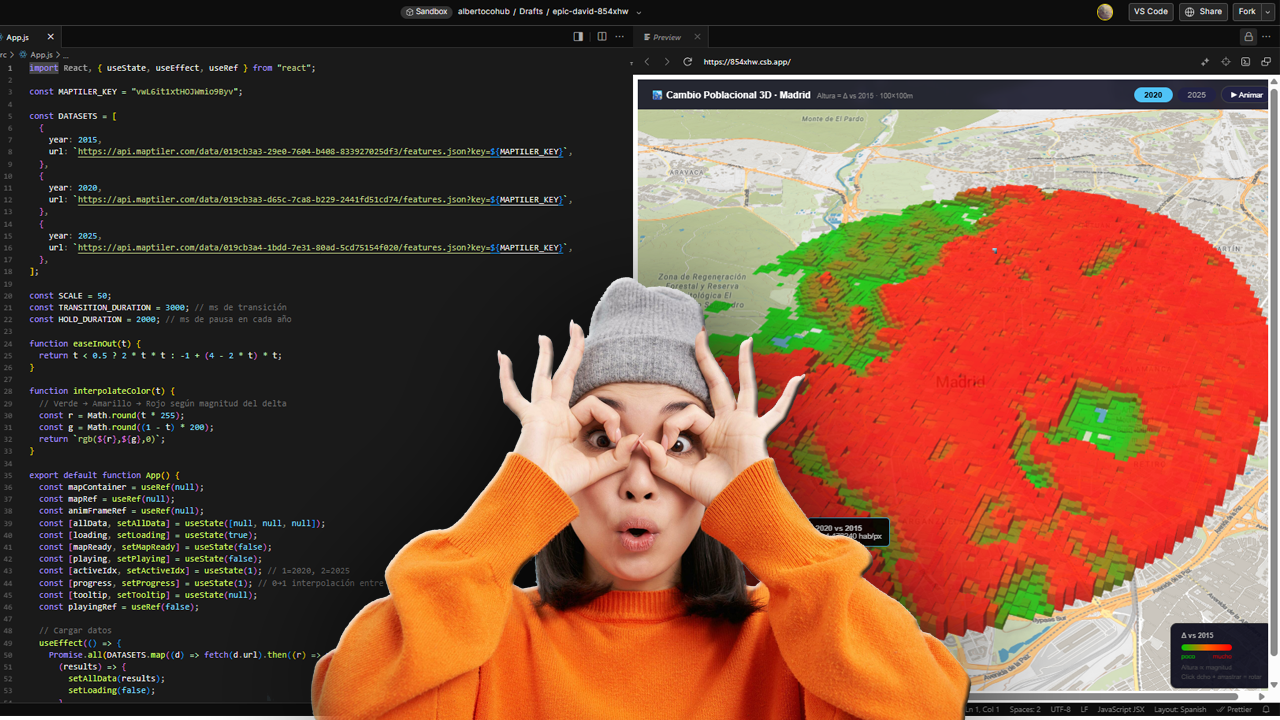
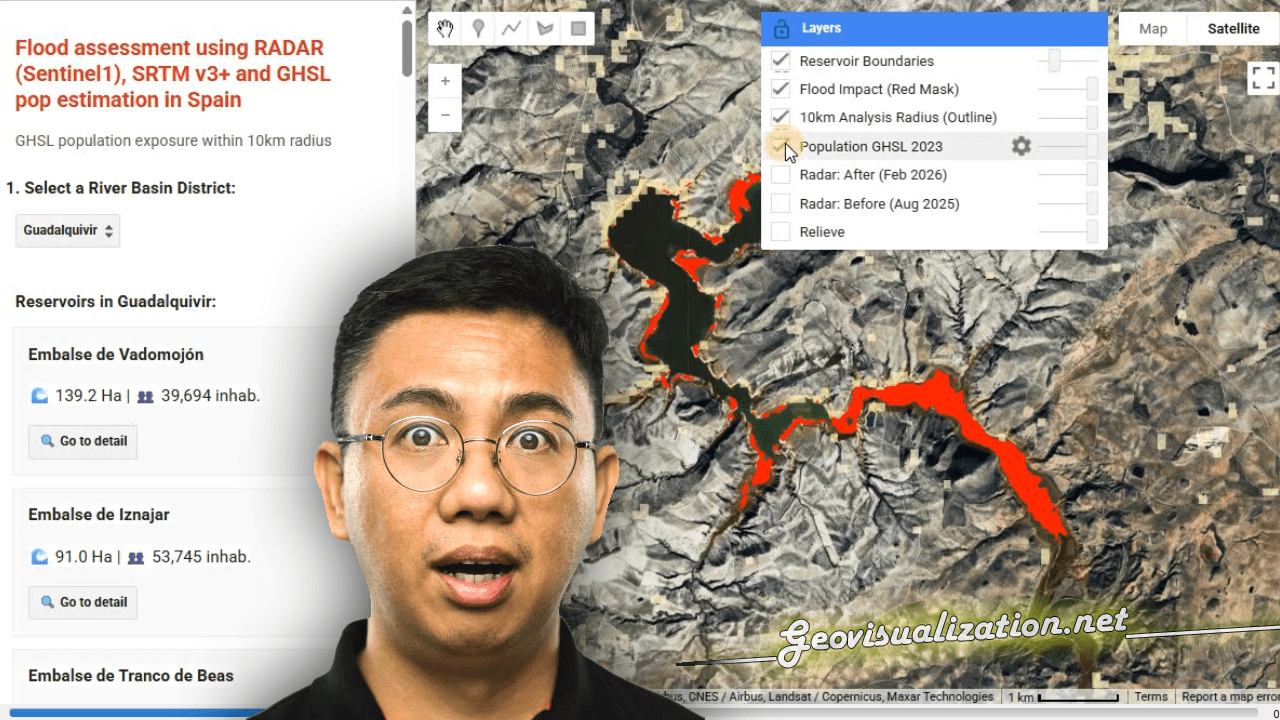
Modern geospatial workflows increasingly depend on fast, reliable access to city-scale vector data — building footprints, road networks, land use polygons, points of interest, address databases. Whether you are designing a 5G radio network, modelling urban heat islands, planning last-mile logistics, or simulating emergency response coverage, you almost always start from the same question: “How do I get clean, structured geodata for this city, right now, without spending two days on it?”
The Overture Maps Extractor is my answer to that question. It is a Shiny application written in R that lets any GIS professional extract multiple thematic layers from the Overture Maps Foundation dataset — for any city in the world — in a matter of minutes, with zero command-line interaction and zero manual data wrangling.