Un registro constante: más de 11 años (desde Agosto 2014 hasta hoy) con más de 1,150 sesiones documentadas. Un proyecto vital; no son solo números, es la cronología de mi disciplina. Puedo decir de nuevo que R me ha roto mis esquemas de geógrafo de ArcGIS, de Global Mapper y QGIS, ahora no todo pasa por el filtro de tener coordenadas, por ejemplo estos insights no tienen coordenadas pero son analizables y se pueden tomar conclusiones que te permiten tomar decisiones rápidas… Echemos un vistazo a mis carreras los últimos años.
Esta década de kilómetros no es solo una base de datos; es una narrativa de superación :-). Para descifrarla, he usado el rigor estadístico de R, que me permite “limpiar” el ruido del esfuerzo diario mediante el uso de percentiles, transformando variables caóticas en tendencias de rendimiento.
El recorrido que he diseñado sigue una secuencia lógica de descubrimiento:
- La Densidad: Primero visualizamos la “forma” de tu carrera, identificando dónde se concentra tu volumen habitual mediante crestas de densidad.
- La Composición: Luego diseccionamos tu “ADN” anual con gráficos de donas para entender el peso relativo de la intensidad vs. el volumen.
- El Radar: Finalmente, llegamos a la joya de la corona: una brújula radial que actúa como un mapa de calor estacional. Aquí, la precisión de R para gestionar gradientes tricolores se une a la estética de proyección polar, permitiéndote ver cómo tu rendimiento “orbita” alrededor de los meses y cómo tu esfuerzo se expande año tras año. Es la unión perfecta entre la estadística descriptiva y la visualización de datos de alto impacto.
Antes de empezar, mi último 2025 que será por cierto el último de este tipo. Los años no pasan en balde y mi próximo proyecto running personal tendrá mucho que ver con el GIS (Python, R) pero eso os lo contaré otro día!

Empecé a darle vueltas a qué hacer y después de mucho tiempo (una semana, juasssss) me pareció que combinar mis carreras con mis análisis GIS podía ser una buena idea, sobre todo ahora que estoy moviendo mi portfolio para encontrar nuevas oportunidades laborales (trabajo, vamos).
El archivo csv contiene columnas clave como un ID, el trimestre, la fecha exacta en formato dd/mm/yyyy, la distancia total (en km), el ritmo (pace, en min/km), el esfuerzo (cociente entre distancia y ritmo), el esfuerzo que toma en cuenta el desnivel recorrido (effort_h) y la clasificación desde la primera hasta la última entrada.

Para empezar a darles valor a estos datos y ayudarte con este proyecto, lo primero es quedarse mirando el CSV durante al menos 10minutos, no hacer nada más… una vez (y solo entonces realizado este primera pasito) empezar con los demás 🙂

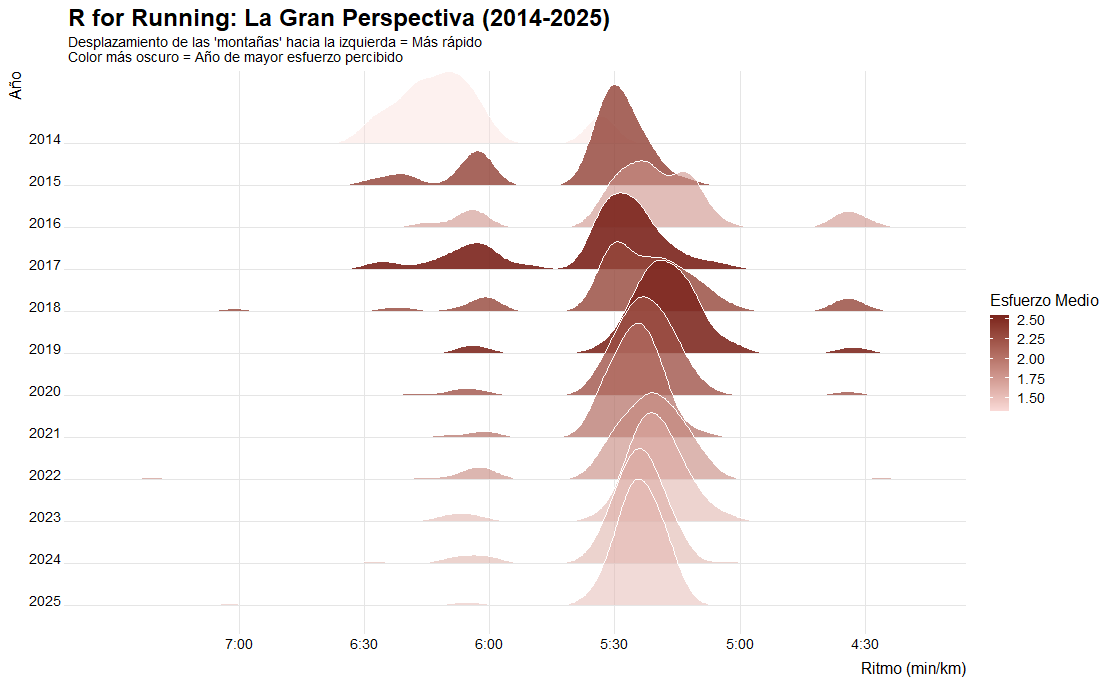
Empecemos a analizar, ¿han sido todos los años iguales? Lo primero que vemos es una constancia y una regularidad infinita, eso es bueno cuando hablamos de coherencia pero hoy no vamos a hablar de coherencia, vamos a hablar de comprensión, de tomar de perspectiva rápida, de toma de decisiones. En lugar de running puedes aplicarlo con casi cada tema. Paso a visualizar todos los años a la vez, todavía no veo mucho pero empiezo a comprender más de la base de datos…

Puntos con Presencia: Al subir el tamaño a 1.5, cada sesión individual ahora tiene peso visual, permitiéndote ver si la línea de tendencia realmente está representando bien la “nube” de ese año.
Claridad en la Leyenda (Label): He añadido el texto el “esfuerzo” (columna effort_h, que mide la relacion entre el tiempo, la distancia y los metros de desnivel positivo) en la parte superior de cada cuadro.

Orden Cronológico Vertical: Puedes ver año tras año cómo la “montaña” de los ritmos se mueve. Si el pico de 2025 está más a la derecha que el de 2014, hay progreso real.
Consistencia vs. Dispersión: Si una montaña es muy alta y estrecha, ese año fui un reloj (siempre al mismo ritmo). Si es baja y plana, fui más irregular.
El Color es el Esfuerzo: El granate oscuro marca visualmente los años donde “me exprimí” más, permitiéndome ver si ese esfuerzo se tradujo en ser más rápido (montaña más a la derecha).
Cero Solapamiento Sucio: Al estar una encima de otra pero ligeramente desplazadas, se puede ver todo sin que nada se tape.

Labels “Ghost”: Las distancias máximas (ej. 21.1k o 42.2k) aparecen en un gris suave (gray40) y con transparencia. Esto permite que el dato esté ahí si lo buscas, pero no ensucie la visión general de la montaña. Cronología Perfecta: El eje X corre de 2014 a 2025 sin saltos.
Referencia de Maratón: He añadido el hito de los 42.2k en el eje de distancias. Cada maratón, verás el “pico” o el label asomando por esa zona en el año correspondiente (arriba del todo están mis tres maratones, mi orgullo máximo, el 2017 en Valencia, el 2019 en Madrid y 2022 en Nantes).
Hitos de secuencia: marcados discretamente el “Inicio” y el “Actual” para dar contexto temporal a la evolución.

Nº de carreras (runs): Da el contexto del volumen. No es lo mismo un año con 100% de intensidad sobre 10 carreras que sobre 100.
ø (Media): Te da el valor exacto del esfuerzo medio anual (effort_h).
Leyenda Descriptiva: He titulado la leyenda de forma más técnica (“Nivel de Esfuerzo”) para que quede claro que los colores representan la variable effort_h.
Limpieza: El uso de theme_void() asegura que toda la atención se centre en la forma y el color de tus datos.

Al usar x = 0.5 en el comando annotate, los números de los años ahora actúan como una “cremallera” que separa el final y el principio de cada ciclo anual, dejando que los colores de todos los meses brillen.
Mapa de Intensidad Completo: La inclusión del Verde permite identificar tus ritmos “crucero” (aeróbicos), diferenciándolos claramente de los días de recuperación (Amarillo) y los de máxima exigencia (Rojo).
Visión 360°: El gráfico ahora parece un instrumento de precisión. Puedes ver perfectamente cómo en ciertos años “conquistaste” la zona roja y en otros te mantuviste en la zona verde/amarilla de base.
Aquí el código del último gráfico:
library(tidyverse)library(lubridate)# 1. CARGA Y FILTRADO (PERCENTILES 10-90)df_radar <- read_delim("run_r.csv", delim = ";", locale = locale(decimal_mark = ","), show_col_types = FALSE) %>% mutate( date = dmy(date), anio = year(date), mes = month(date, label = TRUE, abbr = TRUE), pace_decimal = case_when( ID == 181 ~ 5.516, str_detect(as.character(pace), ":") ~ { p <- str_split(as.character(pace), ":", simplify = TRUE) as.numeric(p[1]) + as.numeric(p[2])/60 }, TRUE ~ as.numeric(str_replace(as.character(pace), ",", ".")) ) )limites <- quantile(df_radar$pace_decimal, probs = c(0.10, 0.90), na.rm = TRUE)# 2. PROCESAMIENTO MENSUALdf_radar_f <- df_radar %>% filter(anio >= 2014, anio <= 2025) %>% group_by(anio, mes) %>% summarise( ritmo_medio = mean(pace_decimal), esfuerzo_total = sum(effort_h), .groups = "drop" )# 3. GRÁFICO CON LABELS ENTRE MESES Y TRICOLORggplot(df_radar_f, aes(x = mes, y = as.factor(anio), fill = ritmo_medio)) + # Celdas de ritmo geom_tile(color = "white", size = 0.2) + # Círculos de esfuerzo (blancos, con tamaño dinámico) geom_point(aes(size = esfuerzo_total), color = "white", alpha = 0.6) + coord_polar() + # ESCALA TRICOLOR: Rojo (Rápido) -> Verde -> Amarillo (Lento) scale_fill_gradientn( colors = c("#C0392B", "#27AE60", "#F1C40F"), # Rojo -> Verde -> Amarillo name = "Ritmo Medio", limits = c(limites[1], limites[2]), oob = scales::squish, labels = function(x) sprintf("%d:%02d", floor(x), round((x - floor(x)) * 60)) ) + scale_size_continuous(name = "Volumen Esfuerzo", range = c(0.5, 9)) + # LABELS DE AÑO: Situados en el borde entre meses (x = 0.5 es entre Dic y Ene) annotate("text", x = 0.5, y = as.factor(2014:2025), label = 2014:2025, color = "gray30", size = 2.8, fontface = "bold", hjust = 0.5) + labs( title = "EVOLUCIÓN DE RENDIMIENTO 2014-2025", subtitle = "Rojo: Velocidad | Verde: Aeróbico | Amarillo: Recuperación\nLos años se indican en la línea divisoria para no tapar los datos", x = "", y = "" ) + theme_minimal(base_size = 14) + theme( panel.grid.major = element_line(color = "gray94", linetype = "dotted"), axis.text.x = element_text(face = "bold", size = 12, color = "black"), axis.text.y = element_blank(), plot.title = element_text(face = "bold", size = 20, hjust = 0.5), plot.subtitle = element_text(hjust = 0.5, size = 11, color = "gray40"), legend.position = "right" )El análisis exhaustivo de esta década de entrenamiento muestra mi capacidad para sostener cargas de trabajo elevadas (y yo no lo sabía!), que ha evolucionado hacia una mayor inteligencia biológica o comprensíón del cuerto de uno mismo, permitiéndome identificar y explotar tus ventanas de máxima eficiencia con una precisión que los registros brutos no alcanzaban a mostrar. Esto es lo que buscaba!
Espero que os haya gustado. En breve más!
Alberto C.
(Geo)data Analyst

Tremendo análisis Alberto, que interesante la forma de poder visualizar y entender todas las variables.
En cualquier caso tu consistencia y coherencia corriendo la tenía clara amigo… jejeje
Muy buen trabajo!!